Subsections
2 Explaining Bayesian Heuristic
Approach by Example of
Knapsack Problem
In the previous chapter we showed how BHA works while
searching for the solution of the knapsack problem. Now we shall
use this problem to illustrate similarities and differences of
various approaches including BHA.
The reason for such special attention is that the knapsack
problem is a simple example of important family of NP-complete
problems![[*]](footnote.png) . Note, that
this example is good mainly for illustration of BHA and alternative
approaches.
The reason is that the simple greedy heuristic of the knapsack
problem is very efficient. Therefore, only marginal improvements can
be made by more sophisticated methods, including BHA. In scheduling problems, such as the flow-shop
and batch scheduling [Mockus et al., 1997], BHA works
more efficiently. However,
the scheduling problems are more difficult for explanations. Thus, we
start the explanations by the knapsack problem.
. Note, that
this example is good mainly for illustration of BHA and alternative
approaches.
The reason is that the simple greedy heuristic of the knapsack
problem is very efficient. Therefore, only marginal improvements can
be made by more sophisticated methods, including BHA. In scheduling problems, such as the flow-shop
and batch scheduling [Mockus et al., 1997], BHA works
more efficiently. However,
the scheduling problems are more difficult for explanations. Thus, we
start the explanations by the knapsack problem.
The knapsack problem is to maximize the total value of a
collection of objects when the total weight  of these objects
is limited. Denote values of objects
of these objects
is limited. Denote values of objects  by
by  and their
weights by
and their
weights by  .
.
Here the objective
 depends on
depends on  Boolean variables
Boolean variables
 .
.
1 Exhaustive Search
The decision  means that a collection of objects
means that a collection of objects
 is selected. The value of the collection is
is selected. The value of the collection is
 . This collection is described by the decision
vector
. This collection is described by the decision
vector
 . The simplest exact
algorithm is to compare all the collections:
. The simplest exact
algorithm is to compare all the collections:
- select a current collection
 ,
,
- record the best current collection
 ,
,
- stop when all
the collections are considered
 .
.
The best current collection denotes the most valuable
collection satisfying the weight
limit that is obtained during  iterations. The best current collection is updated during the
recording operation in step two. It is replaced by better current
collection. The exhaustive search of all the decisions needs
iterations. The best current collection is updated during the
recording operation in step two. It is replaced by better current
collection. The exhaustive search of all the decisions needs
 of iterations. This means
of iterations. This means  of time, where the
constant
of time, where the
constant  is the observation time (the CPU time needed to
evaluate sum (2.1) and to test inequality
(2.2)).
is the observation time (the CPU time needed to
evaluate sum (2.1) and to test inequality
(2.2)).
2 Branch & Bound (B&B)
The efficiency of exact algorithms can be improved by the
Branch & Bound (B&B) techniques:
- define the decision tree,
- define the upper limits of
the branches,
- cut the branch, if the upper limit is less then
the best current collection,
- stop, if there are no more
branches to consider.
For example,
- branch 0:
 , branch 1:
, branch 1:  ,
,
- the upper limit
of branch 1:
the upper limit of branch 0:
- cut branch 0, if
 ,
,
- stop, if there are no
more branches to consider.
In this algorithm, the number of iterations to obtain the exact
solution is  and the time is
and the time is  . Usually,
the time
. Usually,
the time  is much less then the exact upper limit
is much less then the exact upper limit  . However, this limit may be approached. For example, if all
the prices and weights are almost equal. In such
a case no branches will be cut. That is a reason why approximate
algorithms are preferred, if is large.
. However, this limit may be approached. For example, if all
the prices and weights are almost equal. In such
a case no branches will be cut. That is a reason why approximate
algorithms are preferred, if is large.
2 Approximate Algorithms
1 Monte Carlo
The simplest approximate algorithm is Monte-Carlo (MC):
- select a collection
 with
probability
with
probability
- record the best current collection ,
- stop, if the number of iterations
 .
.
Recording just the best current collection, one
samples with replacement. Otherwise, one should keep in the
memory up to  of previous samples. In cases with replacement, one does
not know when the optimum is reached. Therefore, MC stops, if the
time allocated for the optimization is exhausted.
This algorithm converges to an exact solution with probability
one, if the number of iterations
of previous samples. In cases with replacement, one does
not know when the optimum is reached. Therefore, MC stops, if the
time allocated for the optimization is exhausted.
This algorithm converges to an exact solution with probability
one, if the number of iterations
 . However,
the convergence is very slow, nearly logarithmic. Note, that the
time
. However,
the convergence is very slow, nearly logarithmic. Note, that the
time  is not a limit for MC with replacement.
is not a limit for MC with replacement.
2 Greedy Heuristics
Define the heuristic  as the specific value of the object
as the specific value of the object
This "greedy" heuristic is the well known and widely used
in the knapsack problem. The
Greedy Heuristic Algorithms prefer a feasible object with the highest
heuristic :
- select the object with the best heuristic in the
starting list,
- move the object from the starting list
into the current one,
- test feasibility of the collection
which includes this object,
- if the collection is infeasible,
delete the object from the starting list,
- test, whether the
starting list is empty,
- if the staring list is not empty, go
to the step one,
- if the starting list is empty, stop and
record the current list as the best collection , where
 is number of the last iteration.
is number of the last iteration.
The greedy heuristic algorithm is fast,  .
The inequality is there because objects are gradually removed from
the starting list.
The algorithm may stick in some non optimal decision. The greedy
heuristic is obviously useless, if the specific values are
equal
.
The inequality is there because objects are gradually removed from
the starting list.
The algorithm may stick in some non optimal decision. The greedy
heuristic is obviously useless, if the specific values are
equal
 . In such cases the outcome depends
on the numeration of objects.
. In such cases the outcome depends
on the numeration of objects.
3 Randomized Heuristics
1 Linear Randomization
Heuristic algorithms are shaked out of non optimal decisions
by choosing an object with some probability  that is proportional to
the specific value ,
that is proportional to
the specific value ,
This algorithm is similar to that of Greedy Heuristic:
- select an object from the starting list at random
with the probability ,
- move the object from the
starting list into the current one,
- test feasibility of
the collection including this object,
- if the collection is
infeasible, delete the object from the starting list,
- test,
if the starting list is empty,
- if the staring list is not
empty, go to step 1,
- if the starting list is empty, stop and
record the current list as a current collection
,
- record the best current collection ,
- start new iteration
 by restoring starting list to
the initial state (as a set of all the objects) and return to
step 1,
by restoring starting list to
the initial state (as a set of all the objects) and return to
step 1,
- stop after
 iterations and record the best
current collection
iterations and record the best
current collection  .
.
This algorithm is better than the greedy one, in the sense that
it converges with probability one when
.
The algorithm is expected to be better than Monte-Carlo, too,
since it includes an expert knowledge by relating the decision
probabilities to heuristics.
We may choose the preferred heuristic algorithm by considering all
of them separately. Here the quality estimate of each
algorithm is the best result obtained after iterations. That
is a traditional way.
One solves the same problem in a more general setup by
considering a "mixture" of different heuristic algorithms.
For example,
- denote the Monte Carlo by the index
 ,
,
- denote the
Linear Randomization by the index
 ,
,
- denote
the Greedy Heuristics
by the index
 .
.
Then the Mixed Randomization uses the
algorithm denoted by the index  with some probability
with some probability  that is
defined by probability distribution
that is
defined by probability distribution
 :
:
- select an algorithm at random with probability
,
- record the best current collection
 ,
,
- start the new iteration by returning to
step 1,
- stop after iterations and record the best
current collection , denote its value by
 .
.
Here  is the best result obtained using times the
Mixed Randomization with the probability distribution
is the best result obtained using times the
Mixed Randomization with the probability distribution  .
.
That is a way to extend a family of possible decisions from the
discrete set
 to the continuous
one. That is important because the best results we often obtain
using a mixture of algorithms [Mockus et al., 1997].
to the continuous
one. That is important because the best results we often obtain
using a mixture of algorithms [Mockus et al., 1997].
Here we mixed three approximate algorithms: the
Monte Carlo, the Linear Randomization and the Greedy Heuristics.
Following expressions define a larger family of
different approximate algorithms, including these three
and
Here the superscript denotes the Monte-Carlo randomization. The superscripts
 define a family of
"polynomial" randomizations. The superscript
define a family of
"polynomial" randomizations. The superscript  denotes the
greedy heuristics with no randomization.
The Mixed Randomization means using randomization functions
denotes the
greedy heuristics with no randomization.
The Mixed Randomization means using randomization functions
 with probabilities and
recording the best result obtained during
iterations.
The
optimization of the mixture is difficult because is
a stochastic function and the multimodal one, as usual. A
natural way to consider such problems is by regarding functions
as samples of a stochastic function defined by some
prior distribution. The next observation is obtained by
minimizing the expected deviation from the exact solution. This
technique is called the Bayesian Heuristic Approach (BHA)
[Mockus et al., 1997].
with probabilities and
recording the best result obtained during
iterations.
The
optimization of the mixture is difficult because is
a stochastic function and the multimodal one, as usual. A
natural way to consider such problems is by regarding functions
as samples of a stochastic function defined by some
prior distribution. The next observation is obtained by
minimizing the expected deviation from the exact solution. This
technique is called the Bayesian Heuristic Approach (BHA)
[Mockus et al., 1997].
4 Permutation
If we build a solution from "scratch," then we may apply
so-called greedy heuristics [Helman et al., 1993]. Building from
scratch is convenient, if no initial expert
decision is known. Otherwise, building from scratch, one ignores the
expert information included into that initial decision. As usual,
the permutation algorithms are used to improve initial decisions.
In the knapsack problem, the complete collection  is a set
of all objects. The initial collection is a set of objects
is a set
of all objects. The initial collection is a set of objects
 satisfying the inequality
satisfying the inequality
 . The value of this
collection is
. The value of this
collection is  . A complement of the initial set
. A complement of the initial set  is denoted
is denoted  . We denote permuted collections as
. We denote permuted collections as
 and values of these collections as
and values of these collections as
 . We define the direct permutation heuristics as
. We define the direct permutation heuristics as
To avoid confusion, the longer
symbols  and
and  are used sometimes instead of
the short ones
are used sometimes instead of
the short ones  and
and  .
We define the normalized permutation heuristics as
.
We define the normalized permutation heuristics as
where
 and
and
 .
Normalized heuristics (2.9) can be easily
converted into probabilities by expressions such as
(2.6). Direct heuristics (2.8) are
convenient in some well-known algorithms, such as Simulated
Annealing.
Here is an example of permutation algorithm using linear
randomization:
.
Normalized heuristics (2.9) can be easily
converted into probabilities by expressions such as
(2.6). Direct heuristics (2.8) are
convenient in some well-known algorithms, such as Simulated
Annealing.
Here is an example of permutation algorithm using linear
randomization:
- make
 feasible changes
feasible changes
 of the
initial collection , by replacing randomly selected
objects using this algorithm
of the
initial collection , by replacing randomly selected
objects using this algorithm
- select at random with equal probabilities an object
 from initial collection ,
from initial collection ,
- delete this object,
- select at random with equal probabilities an object
 from complement
from complement
 of the initial
collection, skip this step if the complement is empty,
of the initial
collection, skip this step if the complement is empty,
- put
the object into the initial collection,
- test the
weight limit,
return to step one of the replacement algorithm,
if the updated collection is to heavy,
- define normalized permutation heuristics for all
the changes
 ,
,
- define probabilities
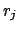 by
expression (2.13),
by
expression (2.13),
- select current collection
at random with probability ,
- record the best current collection ,
- stop after
iterations and record the best current collection .
1 Simulated Annealing
The Simulated Annealing (SA) is a popular global optimization method. Features of SA, considering it as a
permutation algorithm, are:
- only one permutation is made,
 ,
,
- the direct heuristic is used
- if  , the new collection
, the new collection  is selected with probability one,
is selected with probability one,
- if  , the new collection is selected with probability
that declines exponentially,
, the new collection is selected with probability
that declines exponentially,
Here is the iteration number and is the "initial
temperature." The difference of this formulation from
traditional simulating annealing algorithms is that we optimize
the parameter for some fixed number of iterations . We
disregard the asymptotic behavior. The asymptotic properties are
beyond the scope of the Bayesian Heuristics Approach.
2 Genetic Algorithms
Genetic Algorithms (GA) present a
general and visual way of permutation and randomization. GA is a
methodology for searching a solution space in the manner
similar to the natural selection procedure in biological
evolution [Holand, 1975]. Each candidate solution is
represented by a string of symbols. The set of solutions at some
state is called the population of the th generation. The
population evolves for a prescribed number  of generations.
The basic structure processed by GA is the string. Strings are
composed of a sequence of characters.
of generations.
The basic structure processed by GA is the string. Strings are
composed of a sequence of characters.
A simple GA consists of
- one reproductive plan, defined as
the fitness proportional reproduction
- two genetic operators,
defined as crossover and mutation.
The probability of selection
is defined in proportion to the fitness of individuals
During the crossover operation one splits two selected strings at
some random position  . Then two new strings are created, by
exchanging all the characters up to the split point .
During the mutation operation one alters some string characters at
random. A mutation is of -th order, if one changes
elements during one mutation operation. Both the crossover and
the mutation are feasible, if they satisfy all constraints.
. Then two new strings are created, by
exchanging all the characters up to the split point .
During the mutation operation one alters some string characters at
random. A mutation is of -th order, if one changes
elements during one mutation operation. Both the crossover and
the mutation are feasible, if they satisfy all constraints.
It follows from this definition that GA may be considered as a special
case of the Permutation and Randomization. Thus, one may include
GA into the framework of Bayesian Heuristic Approach. We illustrate that by using the Knapsack problem as an example.
In the Knapsack example the string of the collection  is represented as the Boolean vector
is represented as the Boolean vector
The fitness of feasiblecollection  is . The probability to select a string
is
is . The probability to select a string
is
where is the normalized
permutation heuristics
Here
 and
and
 .
.
During the crossover operation one splits two selected strings at
some random position  . Then two new strings are
created, by exchanging all the characters up to the split point
.
. Then two new strings are
created, by exchanging all the characters up to the split point
.
During the mutation operation one produces mutants by
inverting randomly selected components  of the Boolean
vector
of the Boolean
vector  . A mutation is of -th order, if one
changes
. A mutation is of -th order, if one
changes
 components during one mutation
operation. A mutant is fertile, if it satisfies all the
constraints.
components during one mutation
operation. A mutant is fertile, if it satisfies all the
constraints.
Denote by  a current collection at th
iteration. Denote by the best current collection
obtained during iterations.
a current collection at th
iteration. Denote by the best current collection
obtained during iterations.
Here is an example of a simple GA algorithm written in BHA terms.
The algorithm is similar to that of Permutation.
- produce a number of fertile mutants by replacing
randomly selected objects using feasible changes
of the initial collection ,
- define
normalized permutation heuristics
 for all
these mutants using expression (2.14),
for all
these mutants using expression (2.14),
- define probabilities by expression (2.13),
- select two mutants
 and
and  at random
with probabilities ,
at random
with probabilities ,
- select a split point at random with probability

- inverse the components
 and
and
 of these two mutants,
of these two mutants,
- update normalized
permutation heuristics reflecting cross-over results
- update probabilities using (2.13)
- select a current collection at random with the
probability ,
- record the best current collection

- go to step 4 with the probability

- produce fertile mutants by feasible changes of the current
collection,
- define normalized permutation heuristics
,
- define probabilities by
expression (2.13),
- select a current collection
at random with the probability ,
- record the best
current collection
 and return to step 11,
and return to step 11,
- stop
after iterations and record the best current collection
.
It is tacitly assumed that some segments of strings
define specific "traits." In such cases, one may "enforce" good
traits by uniting "good" segments. One may expose bad traits
by uniting "bad" segments, too. Then, reproduction plans tend to favor the good
traits and to reject the bad ones.
Thus, the crossover
operation "improves" the population, if the "traits" assumption is
true.
If not, then the crossover may be considered merely as a sort of
mutation. That may help to jump the area dividing separate "local"
minima. However, the similar jump may be accomplished by high order
mutations, too.
As usual [Androulakis and Venkatasubramanian, 1991], mutations are considered as
more "radical" operations as compared with crossovers. That is
correct, if one changes many elements of the "genetic" sequence during
one mutation. This happens, if the mutation order is close to
the string length .
The results of some real life examples of network optimization
[Mockus, 1967] and parameter grouping
[Dzemyda and Senkiene, 1990] show that
low order mutations, when merely a few elements of the decision
vector  are changed, work better. In such cases, the
mutation may be considered as a less radical operation because
fewer components of the vector are changed, as compared with
the crossover operation.
are changed, work better. In such cases, the
mutation may be considered as a less radical operation because
fewer components of the vector are changed, as compared with
the crossover operation.
We may improve efficiency of the
simple GA algorithm by using the crossover rate (see step
eleven of the algorithm) as an optimization variable in the
framework of BHA. This was applied solving the Batch
Scheduling problems [Mockus et al., 1997].
If the crossover
rate is considered as a time function [Androulakis and Venkatasubramanian, 1991], the parameters of this function can be optimized using BHA.
There are two software versions: one in C++ and one is Java. In
the C++ version, prices and weights are generated
randomly. In the Java case,  reflects a real life
example [Malisauskas, 1998]. The optimal probability
reflects a real life
example [Malisauskas, 1998]. The optimal probability  of the greedy
heuristic
of the greedy
heuristic  is near to one, but not exactly one.
Some degree of randomization helps to escape non optimal
decisions.
The randomized procedures
is near to one, but not exactly one.
Some degree of randomization helps to escape non optimal
decisions.
The randomized procedures
 are defined by
(2.6) and (2.7). Both the software versions
consider just three components.
are defined by
(2.6) and (2.7). Both the software versions
consider just three components.
The  version uses the Monte Carlo, the Linear and the
Quadratic randomizations. Corresponding optimization parameters
are
version uses the Monte Carlo, the Linear and the
Quadratic randomizations. Corresponding optimization parameters
are
 . The Monte Carlo and Linear
randomizations and the Pure Greedy heuristic are applied in the
Java version. Corresponding
optimization parameters are
. The Monte Carlo and Linear
randomizations and the Pure Greedy heuristic are applied in the
Java version. Corresponding
optimization parameters are
 .
.
We are looking for such probability distribution that
provides the maximal after iterations. Bayesian
methods [Mockus, 1989a,Mockus and Mockus, 1990,Mockus et al., 1997] are used for
that.
1 C++
The aim of the GMC version is to estimate average error of BHA. A set of knapsack problems with random prices
and weights is considered. The results of BHA and the exact
deterministic B&B algorithms are in Table 2.1.
Average results were obtained by repeating the optimization
procedures  times at fixed parameters and probability distribution .
times at fixed parameters and probability distribution .
Table 2.1:
Comparison of the Bayesian method and the exact one.
 , and , and  |
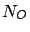 |
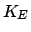 |
 |
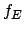 |
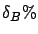 |
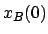 |
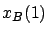 |
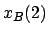 |
| 50 |
313 |
9.56057 |
9.62347 |
0.654 |
0.0114 |
0.0280 |
0.9605 |
| 100 |
526 |
13.0703 |
13.1241 |
0.411 |
0.0316 |
0.0412 |
0.9271 |
| 150 |
771 |
16.6301 |
16.6301 |
0.000 |
0.0150 |
0.1945 |
0.7904 |
| 200 |
875 |
37.4665 |
37.4859 |
0.050 |
0.0315 |
0.0530 |
0.9437 |
| 250 |
568 |
53.7781 |
53.9000 |
0.226 |
0.0091 |
0.0511 |
0.9397 |
| 300 |
1073 |
28.3144 |
28.6106 |
1.034 |
0.0113 |
0.0835 |
0.9050 |
| 350 |
1416 |
30.4016 |
31.7527 |
4.254 |
0.0064 |
0.0646 |
0.9288 |
| 400 |
2876 |
32.1632 |
33.3192 |
3.469 |
0.0202 |
0.0452 |
0.9344 |
| 450 |
1038 |
105.467 |
105.578 |
0.105 |
0.0101 |
0.0149 |
0.9748 |
| 500 |
2132 |
39.3583 |
42.1047 |
6.521 |
0.0078 |
0.1556 |
0.8365 |
In Table 2.1  is the number of objects.
is the number of repetitions.
is the number of objects.
is the number of repetitions.  is the total
number of observations by the Bayesian method. is
the number of nodes considered by the exact method. is the best result of the Bayesian method.
is the exact optimum. is the mean
percentage error of the Bayesian algorithm.
is the total
number of observations by the Bayesian method. is
the number of nodes considered by the exact method. is the best result of the Bayesian method.
is the exact optimum. is the mean
percentage error of the Bayesian algorithm.
 ,
are optimized probabilities of different randomizations
obtained using a Bayesian method.
If the deviation of some solution does not exceed
,
are optimized probabilities of different randomizations
obtained using a Bayesian method.
If the deviation of some solution does not exceed  , we call
this a solution. One can expect that the solution
satisfies the applications, where the level of data uncertainty
is not less than .
, we call
this a solution. One can expect that the solution
satisfies the applications, where the level of data uncertainty
is not less than .
Table 2.1 shows that we need to consider from 313 to
2876 nodes to obtain the exact solution. Only 100 observations
are needed to obtain the solution by the Bayesian method.
The deviation exceeds  only for three cases in ten. The
average deviation is
only for three cases in ten. The
average deviation is  .
.
Assume that roughly the same computing time is necessary for one
node and for one observation. Then the Bayesian
solution is about three times "cheaper" as compared to the
exact one, if the number of objects is fifty. If this number is
400, then the Bayesian solution is almost thirty times
cheaper.
Other examples, in particular ones applying BHA to a family of
scheduling problems [Mockus et al., 1997] show higher efficiency
of BHA.
2 Java
Here w
e optimize a "mixture" of the Monte Carlo randomization,
the linear randomization, and the pure greedy heuristic. The
aim is to show how BHA works while solving a real life knapsack
problem. The example illustrates how to apply the Java software
system for global optimization called as GMJ1. Therefore, several
figures are included. They illustrate the input and output of GMJ1
graphical interface.
The data represents the weights, the values, the numbers, and
the names of inventory items of the "Norveda" shop that sells
"Hitachi" electrical tools. Table 2.2 shows a
fragment of data file 'norveda.txt'.
Table 2.2:
A fragment of data file
'norveda.txt.'
| Weight |
Value |
Number |
Name |
| 3.8 |
2830 |
1 |
CNF35U |
| 10.5 |
4170 |
2 |
CNF65U |
| 11.5 |
3850 |
1 |
CM12Y |
| 1.8 |
1500 |
2 |
CE16 |
| 1.7 |
1500 |
2 |
CN16 |
| 17.0 |
2100 |
4 |
CC14 |
| 20.9 |
2890 |
2 |
J9312N |
| 0.9 |
330 |
8 |
D6SH |
| 1.7 |
1170 |
10 |
D10YA |
| 1.3 |
630 |
5 |
D10VC |
|
Here fields,
separated by spaces, denote these parameters of objects:
- weights (double),
- prices
(double),
- numbers (integer),
- names
(string).
The algorithm is implemented as a  of the GMJ1 system.
Figure 2.1 shows a fragment of the file
'Knapsack.java'
of the GMJ1 system.
Figure 2.1 shows a fragment of the file
'Knapsack.java'
Figure 2.1:
A fragment of the knapsack program.
 |
Figure 2.2 (top) shows the input page.
On  fields,
fields,
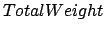
- is the weight limit, from 10
to 10.000,
-
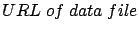
- is the URL address.
This data file is on the same server as the
applet. If the data is not correct, the corresponding field turns
red. In the black-and-white figure 2.2, red is shown
as the dark shadow. Therefore, the incorrect URL
address is not legible.
On the  fields,
fields,
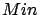
- is the minimal value of ,
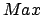
- is the maximal value of ,

- is the default value of .
The values show the proportions of each method. The
mixture of three methods of picking objects is considered: the
Monte Carlo, the Linearly Randomized Heuristics and the pure
Greedy Heuristics. Probabilities  of methods
of methods  are related to the proportions this way
are related to the proportions this way
 .
.
Figure 2.2:
Input page (top) and output page (bottom).
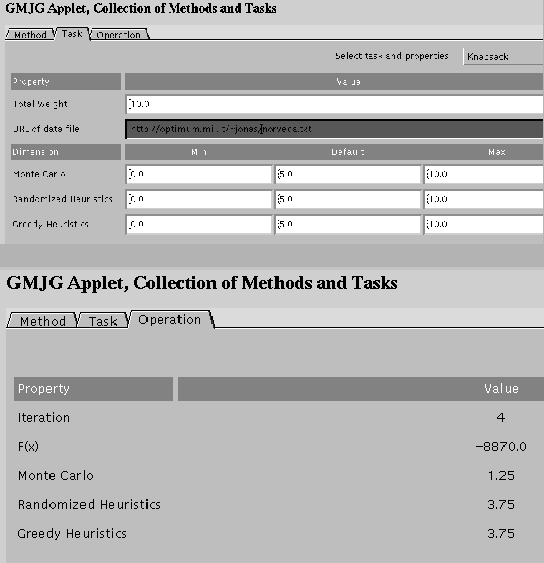 |
Figure 2.2 (bottom) shows the output page that opens when
the computing is completed. Here  means the iteration
number where the best value was reached.
means the iteration
number where the best value was reached.  defines the best
value, "Monte Carlo." "Randomized Heuristics," and "Greedy
Heuristics" show the optimal part of each of the three methods
in the mixture.
defines the best
value, "Monte Carlo." "Randomized Heuristics," and "Greedy
Heuristics" show the optimal part of each of the three methods
in the mixture.
Figure 2.3 (top) shows how the best value of
changes subject to the iteration number.
Figure 2.3 (bottom) shows how changes subject to
proportions of the Monte Carlo randomization.
Figure 2.3:
The best obtained value subject to iteration numbers (top), the objective function subject to proportions of the
Monte Carlo randomization (bottom).
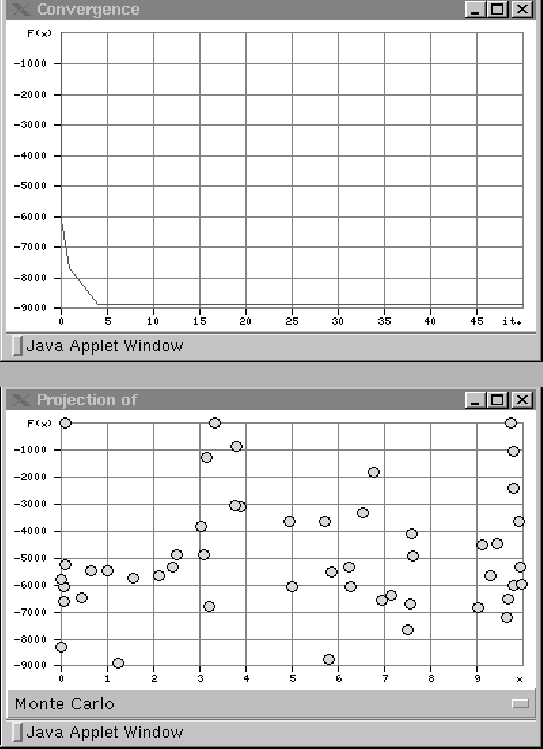 |
Figure 2.4 (top) shows how changes subject to
proportions of the linear randomization.
Figure 2.4 (bottom) shows how changes subject to
proportions of the pure greedy heuristics.
Figure 2.4:
The objective function subject to proportions of the
linear randomization (top), the objective function subject to proportions of the
pure greedy heuristics (bottom).
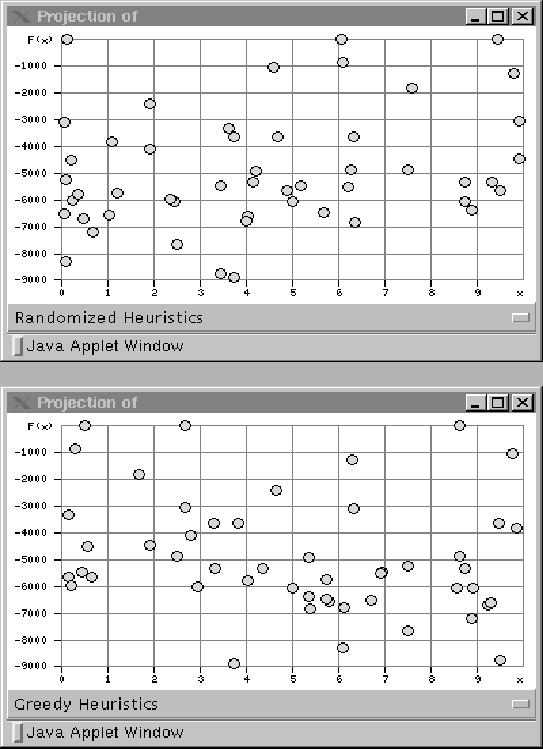 |
It is hard to notice any regularity in the  windows
in Figures 2.3 (bottom), and 2.4.
The reason is that all the variables change together during the
optimization. To see good projections, one uses the method
windows
in Figures 2.3 (bottom), and 2.4.
The reason is that all the variables change together during the
optimization. To see good projections, one uses the method  . Variables
change one by one in this method (see Figures 9.4 and 9.5).
. Variables
change one by one in this method (see Figures 9.4 and 9.5).
Figure 2.5:
Table of results
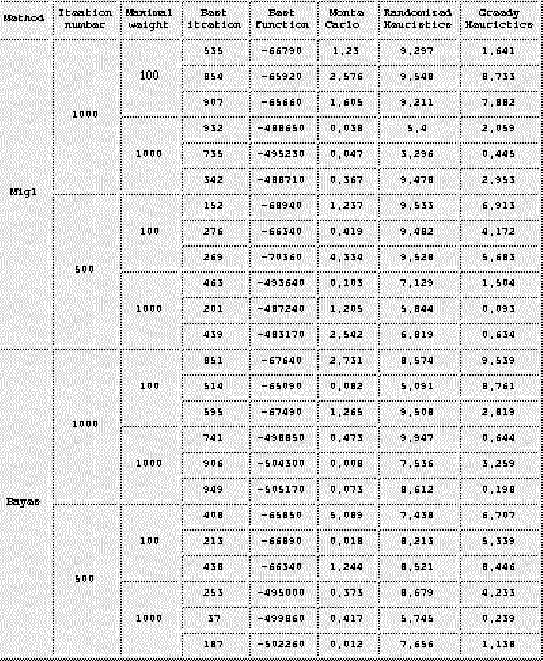 |
Table 2.5 shows how the results of
optimization depend on the optimization method (the first
column), the number of iterations ( the second column), and the
weight limit (the third column). The fourth column shows the
iteration number where the best value was obtained, the fifth
column shows the best value. The sixth, the
seventh, and the eighth column define the optimal mixture of
three search methods. These mixtures can be expressed in
percentage terms dividing each of the three numbers by their
sum and multiplying by 100.
The results suggest that
- doubling the iteration number (from 500 to 1000) we lower
the average error just by
 ,
,
- if the weight limit is
high, the greedy heuristic is almost useless (the optimal
mixture
 meaning that the greedy heuristics
part is just 1/15,
meaning that the greedy heuristics
part is just 1/15,
- if the weight limit is
low, the greedy heuristic is essential (the optimal mixture
 because the greedy heuristics part is
ten times greater.
because the greedy heuristics part is
ten times greater.
Now we consider some related problems.
In these problems there are no obvious heuristics. Therefore, designing BHA algorithms one should consult experts.
The experts may define decision rules defining greedy heuristics or suggest initial solutions needed for permutation heuristics.
The objective is to collect the minimal number of trains to remove cars from a goods-station.
Optimization variables are  . Here
. Here
 denotes a car and
denotes a car and 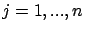 denotes a train.
The Boolean variable
denotes a train.
The Boolean variable  , if
the car is assigned to the train
, if
the car is assigned to the train  . Otherwise
. Otherwise  .
.
The
constraints are
Here
 is the weight of car .
is the weight of car .
 is the maximal weight of train .
is the maximal weight of train .
 is length of car .
is length of car .
 is maximal length of train .
is maximal length of train .
The objective function is the number of trains
The task is to cut a rod of length  into pieces of
length
into pieces of
length
 with minimal waist
with minimal waist  .
Optimization variables are
.
Optimization variables are  .
.
Here
denotes a segment.
 defines an ordinal
number of the segment.
defines an ordinal
number of the segment.
The Boolean variable  ,
if
the segment is assigned to the rod with ordinal number
,
if
the segment is assigned to the rod with ordinal number  .
.
Otherwise,  .
.
The
constraint is
Here
is length of segment including the saw section.
is length of rod.
No gaps between segments.
The objective function is the waist.
The waist  is defined as the difference between
the length of the rod and the sum
is defined as the difference between
the length of the rod and the sum  of lengths of all the segments cut,
of lengths of all the segments cut,
 .
One needs the optimization, if the sum of lengths of all segments to be cut
.
One needs the optimization, if the sum of lengths of all segments to be cut  .
.
If there are  rods of length
rods of length
 to be cut into segments
then one minimizes the total waist
to be cut into segments
then one minimizes the total waist
Here
 ,
,
 ,
,
 ,
,
index is denotes a segment.
index denotes a rod,
index defines an ordinal
number of the segment in the rod .
The Boolean variable  ,
if
the segment is assigned to the rod with ordinal number .
,
if
the segment is assigned to the rod with ordinal number .
Otherwise .
The optimization is needed if
 .
.
The exact solutions are practical only for small problems.
For larger problems one can apply all the heuristic methods described in the knapsack section 2.
Only heuristics of the optimal cut problem are different from those used in the knapsack problems and should be defined by experts. The trivial heuristic is the length of a segment . Using randomization techniques this means assigning higher probabilities to segments of greater length.
The task is to produce boards with minimal waist. There are timbers.
Optimization variables are  .
.
Here
is denotes a board.
denotes a timber.
defines an ordinal
number of the board in the timber .
The Boolean variable ,
if
the board is assigned to the timber with ordinal number .
Otherwise .
The
constraints are
Here
is width of board including the saw section.
 is diameter of timber
at the location of board .
is diameter of timber
at the location of board .
That means, depends
on the order and of boards in the timber and their thickness .
No gaps between boards.
The objective function is the waist
 .
The waist
is defined as the difference between
the cross-section area of all timbers used and the sawn section of all boards produc
Expression (2.21) defines constraints for the simple composition of timbers (see Figure 2.6)
.
The waist
is defined as the difference between
the cross-section area of all timbers used and the sawn section of all boards produc
Expression (2.21) defines constraints for the simple composition of timbers (see Figure 2.6)
Figure 2.6:
Simple composition
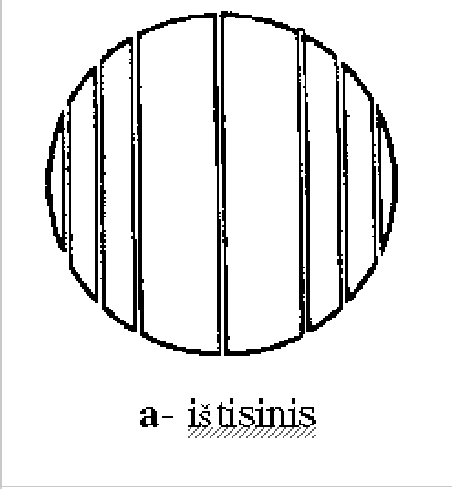 |
For more complicated compositions, for example, the segment one (see Figure 2.7), different constraints should be defined.
Figure 2.7:
Segment composition
 |
As usual, the food is sold in supermarkets and meals are served in restaurants only in some units.
For example one cannot buy one third of bottle of milk or order two thirds of hamburger.
In this case solving the optimal diet problem one faces difficulties similar to those in the knapsack problem.
The reason is that some of optimization variables are integer including the binary ones that we shall regard separately.
One minimizes the extended costwhile keeping some health constraints
Here
index denotes an item of diet,
denotes the unit price,
 is the number of units,
is the number of units,
 is the amount of pleasure, obtained while consuming a unit of the food and estimated as some benefit in money terms,
is the amount of pleasure, obtained while consuming a unit of the food and estimated as some benefit in money terms,
 is the amount of calories in the item ,
is the amount of calories in the item ,
 is the amount of some basic food ingredients ,
such as proteins, hydrocarbons, fats, etc.,
contained in a unit of item ,
is the amount of some basic food ingredients ,
such as proteins, hydrocarbons, fats, etc.,
contained in a unit of item ,
 defines amounts needed to keep healthy,
defines amounts needed to keep healthy,
 the unpleasant
results due to excess calories estimated ass some losses in money terms.
the unpleasant
results due to excess calories estimated ass some losses in money terms.
The exact solution of the diet problem (2.22-(2.24)
can be obtained by the Mixed Integer Linear Programming (MILP). The free MILP software in Java is
in the web-sites (see section "Software Systems",
under the title "LPJ").
However, one observes the exponential growth of time
depending on the number of integer variables,
mainly the binary ones. Therefore, one prefer approximate methods, if the number of those variables is large.
This means approximating integer variables
by continuous ones. This way the Mixed Integer Linear Programming (MILP) problem is reduced to the simple
Linear Programming (LP).
The disadvantages are large round-off errors.
The rounding uncertainty of binary variables makes LP solution almost irrelevant.
First we separate the easy part
of the diet problem from the hard one.
The original MILP problem (2.22-(2.24) is replaced
by a set of LP problems corresponding to all possible
combinations of integer variables represented by the vector
 .
.
Theoretically, one obtains the exact solution by comparing all possible values of the discrete vector  .
.
This is not practical, except for very small numbers  and
and  because the number of different is
because the number of different is
 .
.
The practical advantage of the formulation (2.25)-(2.28) is
that using this formulation one can directly apply all the heuristic methods described in the knapsack example.
The specific structure of the diet problem is exploited
by defining the greedy heuristics
or by setting a proper initial diet to be improved later by
permutations. The second way seems convenient for the diet problem, because one just improves the diet that a person already likes. By using greedy heuristics
one designs new diets from scratch.
In all the cases the BHA helps to optimize the heuristic parameters (see the section 2).
Only continuous variables are optimized. That is appropriate while considering only the basic food items such as bread, milk, butter, juice, etc.
The diet taste is included indirectly, first, by selecting
the food list, then, by choosing the most favored item.
The Figure 2.8
Figure 2.8:
Input and Output of the Diet Problem.
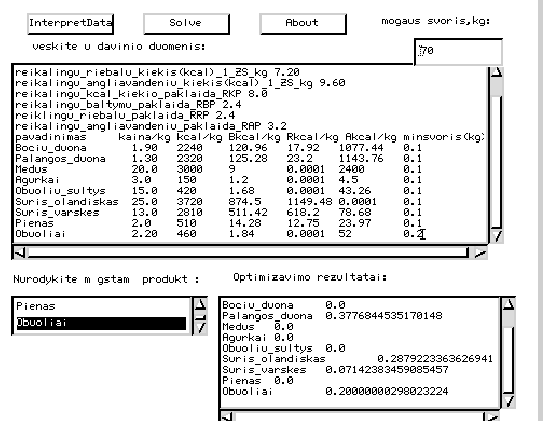 |
shows the input data and the results of optimization.
The selected list reflects the vegetarian taste.
The most favored item are apples.
The upper window shows the selected list and related data.
The lower-right window shows the optimization results.
Note, that there are only four non-zero items
because there are only four constraints
defining lower limits for calories, proteins, fats and carbohydrates. This is a specific property of the linear programming solutions.
Travelling salesman problem
The problem is to minimize the total path length of a salesman
visiting cities and returning home (see[Miller and Pekny, 1991]).
Formally, a decision is a sequence of numbers
 that defines the sequence of visits to diferent cities
that defines the sequence of visits to diferent cities
 .
.
A
decision is feasible  if there are no gaps in the path. The feasible decision is optimal if
if there are no gaps in the path. The feasible decision is optimal if
where  is the length of path .
is the length of path .
Here the vector  defines coordinates
of the city number
defines coordinates
of the city number  .
In the two-dimensional space
.
In the two-dimensional space
 .
The distances between the cities are defined as Euclidean distances
between the corresponding points
.
The distances between the cities are defined as Euclidean distances
between the corresponding points  .
.
In the following numerical experiments "cities" are considered to be points  in the
ten-dimensional unit cube [Mockus et al., 1997]. The multi-dimensional case is convenient for comparison of different methods.
The reason is that the choice of alternative paths is wider here.
in the
ten-dimensional unit cube [Mockus et al., 1997]. The multi-dimensional case is convenient for comparison of different methods.
The reason is that the choice of alternative paths is wider here.
Besides, in some real life traveling salesman problems, more then two dimensions are regarded.
For example, if a global traveling salesman is sensitive to the time lag then the third dimension is time.
If a product
passes through many separate reactors then one minimizes differences of some parameters between adjacent reactors, in addition to geometric coordinates.
Consider the heuristics
Here  is with the minus sign, because we regard greater heuristics as the better ones.
The greedy decision is to visit nearest new city
is with the minus sign, because we regard greater heuristics as the better ones.
The greedy decision is to visit nearest new city
It is well known that the "nearest city" heuristic
provides nearly optimal solutions, as ususal.
Thus, this heuristic should be the main component
of any efficient heuristic algorithm.
However, to provide for convergence conditions [Mockus et al., 1997], some randomization should be introduced, too.
Considering the knapsack example
the compromise between the efficiecy of pure greedy heuristics and the convergence conditions
is provided by adding deterministic component (2.34) representing greedy heuristics to the stochatsic components represented as polynomial (2.33).
and
Here the superscript denotes the Monte-Carlo randomization. The superscripts
define a family of
"polynomial" randomizations. The superscript denotes the
greedy heuristics with no randomization.
In the traveling salesman example considered in [Mockus et al., 1997] the similar objective
was approached by the "sharp" polynomial expression
of probabilities
where  is large.
is large.
Using the Bayesian Heuristic Approach [Mockus et al., 1997] the randomization functions
are aplied with probabilities . The
best results obtained during
iterations are recorded.
The minimum of function is achieved optimizing the "mixture" of different randomization techniques .
The
optimization of the mixture is difficult because is
a stochastic function and the multimodal one, as usual.
That is a reason why the Bayesian methods
are applied to minimize .
In the numerical examples [Mockus et al., 1997] only three terms were considered  .
Best results were obtained using number
.
Best results were obtained using number  . In this case, the probability of going to
some distant city is almost zero. However, even very small
deviation from the pure heuristics is significant. For example,
the probability of not going to the nearest city (in a problem of 100 cities) is about
in one iteration and about
. In this case, the probability of going to
some distant city is almost zero. However, even very small
deviation from the pure heuristics is significant. For example,
the probability of not going to the nearest city (in a problem of 100 cities) is about
in one iteration and about  in all 100 iterations.
One may consider these sparse "deviations" from the pure heuristic decisions
as some new "initial" points preventing the heuristics to be trapped. This is a way to provide the convergence.
in all 100 iterations.
One may consider these sparse "deviations" from the pure heuristic decisions
as some new "initial" points preventing the heuristics to be trapped. This is a way to provide the convergence.
The number of cities is from 100
to 500. points (representing cities) are generated 300 times, by sampling from a uniform distribution in the
10-dimensional unit cube.
Usually the exact optimum is not obtained, because the number of
problems ( ) and the size of the problems (from 100 to 500
cities) is too large. Consequently we merely compare the Bayesian methods with
the pure heuristics. Both a simple sequential nearest
city algorithm and a more complicated local permutation algorithm
are considered.
) and the size of the problems (from 100 to 500
cities) is too large. Consequently we merely compare the Bayesian methods with
the pure heuristics. Both a simple sequential nearest
city algorithm and a more complicated local permutation algorithm
are considered.
2 Permutation Heuristics
For purposes of the algorithm involving local permutations, some
initial travel path must be used. One tries to improve this initial fixed path by selecting a
pair of adjacent cities  and afterwards considering another pair of
adjacent cities
and afterwards considering another pair of
adjacent cities  . The pairs are chosen so that reconnecting to
. The pairs are chosen so that reconnecting to
 and
and  to
to  we still obtain a path that visits all cities. We seek
such a new path that is shorter. The initial path is selected by a
greedy heuristic, then we repeat times the following two
steps:
we still obtain a path that visits all cities. We seek
such a new path that is shorter. The initial path is selected by a
greedy heuristic, then we repeat times the following two
steps:
- choose the first pair of cities at random;
- consider the remaining pairs in succession as long
as a shorter path
 is found, .
is found, .
The local permutation heuristics  where
where  is
the total length of travelling salesman path corresponding to the permutation .
is
the total length of travelling salesman path corresponding to the permutation .
Table 2.3 illustrates the results of Bayesian algorithms employing simple
greedy heuristics by selecting nearest neighbor. The results of pure greedy heuristics and that
of pure local permutation are shown, too, for comparison.
Table 2.3:
Results of the Bayesian method using
greedy heuristics.
|
|
 |
|
 |
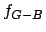 |
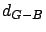 |
| 100 |
64 |
78.90 |
77.62 |
77 |
1.28 |
0.39 |
| 200 |
128 |
144.88 |
143.30 |
142 |
1.58 |
0.71 |
| 300 |
128 |
205.90 |
203.95 |
202 |
1.95 |
0.85 |
| 400 |
128 |
264.62 |
262.63 |
260 |
1.99 |
1.05 |
| 500 |
128 |
321.35 |
319.10 |
316 |
2.25 |
1.32 |
In this table the letter  stands for the Bayesian method, the letter
stands for the Bayesian method, the letter  denotes pure greedy heuristics, and the symbol
denotes pure greedy heuristics, and the symbol  denotes pure local
permutations. The table provides sample means
denotes pure local
permutations. The table provides sample means  and sample variances
. Thus denotes the mean of the difference between the
results of a greedy heuristic and the Bayesian methods, and
denotes the corresponding variance. The symbol stands for the
number of cities, and the letter is the power of the "sharp" polynomial
(see expression (2.35). The Bayesian method performs 46
observations.
and sample variances
. Thus denotes the mean of the difference between the
results of a greedy heuristic and the Bayesian methods, and
denotes the corresponding variance. The symbol stands for the
number of cities, and the letter is the power of the "sharp" polynomial
(see expression (2.35). The Bayesian method performs 46
observations.
The results show that the Bayesian method is roughly better than
the pure greedy heuristic. The improvement declines with the size of
the problem, from  for
for  to
to  for
for  .
Comparing the columns and
.
Comparing the columns and  we see the advantage of
local permutation heuristics. Therefore, the
Bayesian method is applied here, too.
Table 2.4 demonstrates the results of Bayesian algorithms for the case of local permutation heuristics. The results of pure greedy heuristics and that
of pure local permutation are shown, too.
we see the advantage of
local permutation heuristics. Therefore, the
Bayesian method is applied here, too.
Table 2.4 demonstrates the results of Bayesian algorithms for the case of local permutation heuristics. The results of pure greedy heuristics and that
of pure local permutation are shown, too.
Table 2.4:
Results of the Bayesian
method using permutation heuristics.
|
|
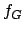 |
|
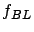 |
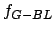 |
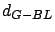 |
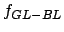 |
| 100 |
32 |
78.7 |
77 |
76 |
2.7 |
0.6 |
1 |
| 200 |
32 |
144.5 |
142 |
140 |
4.5 |
0.7 |
2 |
| 300 |
32 |
206.1 |
202 |
200 |
6.1 |
1.2 |
2 |
| 400 |
32 |
265.3 |
260 |
258 |
7.3 |
1.4 |
2 |
| 500 |
32 |
321.5 |
316 |
313 |
8.5 |
1.5 |
3 |
In Table 2.4 the symbol  stands for the Bayesian method, the symbol
denotes a pure local permutation heuristic. The table provides
sample means and sample variances . Thus, the symbol
denotes the average difference between the pure local permutation
heuristic and the Bayesian method. The symbol denotes the
average difference between greedy heuristics and the Bayesian
method using local permutations. The symbol denotes the
corresponding variance. Here the Bayesian method performed 26
observations and the algorithm stops after 50
repetitions.
stands for the Bayesian method, the symbol
denotes a pure local permutation heuristic. The table provides
sample means and sample variances . Thus, the symbol
denotes the average difference between the pure local permutation
heuristic and the Bayesian method. The symbol denotes the
average difference between greedy heuristics and the Bayesian
method using local permutations. The symbol denotes the
corresponding variance. Here the Bayesian method performed 26
observations and the algorithm stops after 50
repetitions.
Sharp polynomial randomization (2.35) was chosen as a result of some additional
experimentation. When the uniform distribution was included, the average value of was  for
(one hundred cities). Using expression (2.35) with
for
(one hundred cities). Using expression (2.35) with
 , the average value of was
, the average value of was  for the same .
The best average gain was achieved with (see Table 2.4).
The distribution of coefficients
for the same .
The best average gain was achieved with (see Table 2.4).
The distribution of coefficients  from expression (2.35) shows which powers of are most important
in calculating
from expression (2.35) shows which powers of are most important
in calculating  .
.
The results of Table 2.4 show that the Bayesian method is approximately
better than the pure heuristics (see the average gain ). The improvement
is almost independent of the size of the problem. We consider to be
a good result, because this improvement is obtained near the global minimum,
where even a fraction of percent is important.
Here four algorithms are implemented in Java 1.1:
the author calls them the
 , the
, the
 , the
, the  , and the
, and the
 .
Figures 2.9 show the nearest neighbor and the repeated nearest neighbor examples. The repeated nearest neighbor starts from random starting points. Two optimal is a version of the permutation algorithm described in the section 5.2. Two optimal (random)
uses the results of nearest neighbor algorithm
as the starting path.
.
Figures 2.9 show the nearest neighbor and the repeated nearest neighbor examples. The repeated nearest neighbor starts from random starting points. Two optimal is a version of the permutation algorithm described in the section 5.2. Two optimal (random)
uses the results of nearest neighbor algorithm
as the starting path.
Figure 2.9:
The nearest neighbor (top) and the repeated nearest neighbor (bottom) examples .
 |
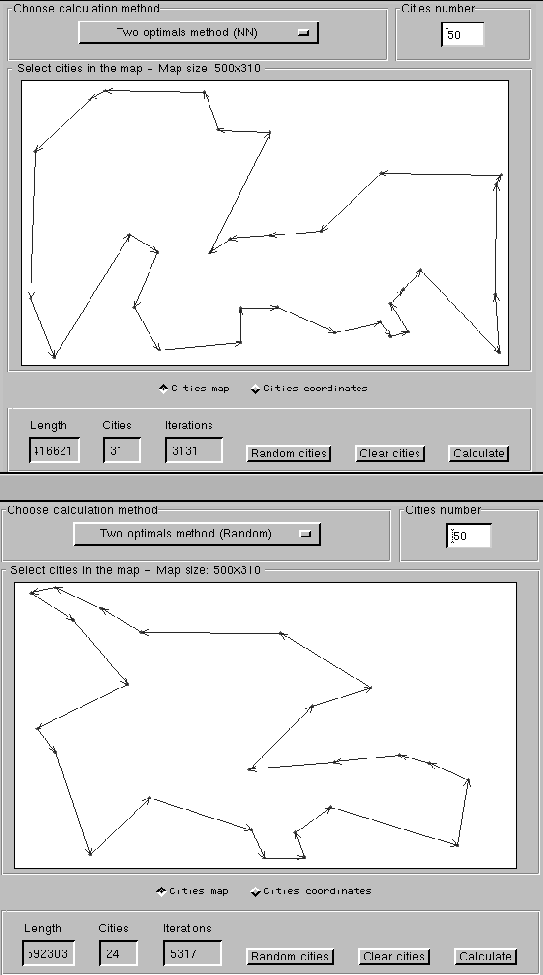
Figures 2.10 show the two optimal and random two optimal examples.
Figure 2.10:
The two optimal (top) and random two optimal (bottom) examples .
 |
In this example two algorithms are regarded:
the
and the  .
Figures 2.11 show the nearest neighbor and the bubble examples. The bubble algorithm is similar to nearest neighbor, however the bubble starts from three connected cities.
.
Figures 2.11 show the nearest neighbor and the bubble examples. The bubble algorithm is similar to nearest neighbor, however the bubble starts from three connected cities.
Figure 2.11:
The nearest neighbor (top) and the bubble (bottom) examples .
 |
The first task is to implement in Java the Bayesian Heuristic Algorithm (BHA) described in the section 3.2 and extend it to permutation heuristic.
Using the permutation heuristics the Bayesian version of Simulated Annealing (see section 2.4) seems to be an interesting alternative to the BHA.
To perform the statistical comparison of these algorithms one prefers Java1.2 implementation
because it works about ten times faster in similar problems.
jonas mockus
2004-03-20














