Next: 2 EXPLAINING BHA BY Up: 1 ABOUT THE BAYESIAN Previous: 1 ABOUT THE BAYESIAN Contents Index
The alternative is the average case analysis. Here an average error is not limited but is made as small as possible. The average is taken over a set of functions to be optimized. The average case analysis is the Bayesian Approach (BA) [Diaconis, 1988,Mockus, 1989a].
There are several ways to apply BA in optimization. The first
one, the Direct Bayesian Approach (DBA), is defined by fixing a
prior distribution ![]() on a set of functions
on a set of functions ![]() and by
minimizing the Bayesian risk function
[DeGroot, 1970,Mockus, 1989a]. The risk function
and by
minimizing the Bayesian risk function
[DeGroot, 1970,Mockus, 1989a]. The risk function ![]() is the
expected deviation from the global minimum at a fixed point
is the
expected deviation from the global minimum at a fixed point ![]() . The distribution
. The distribution ![]() is considered as a stochastic model of
is considered as a stochastic model of
![]() , where
, where
![]() might be a deterministic or a stochastic function. In
the Gaussian case, assuming [Mockus, 1989a] that the
might be a deterministic or a stochastic function. In
the Gaussian case, assuming [Mockus, 1989a] that the
![]() th observation is the last one
th observation is the last one
Another way, the Bayesian Heuristic Approach (BHA), means fixing
a prior distribution ![]() on a set of auxiliary functions
on a set of auxiliary functions ![]() . These
functions define the best values obtained by using
. These
functions define the best values obtained by using ![]() times
some heuristic
times
some heuristic ![]() . It is assumed that
heuristics
. It is assumed that
heuristics ![]() depend on some continuous
parameters
depend on some continuous
parameters ![]() . The heuristic helps to optimize an original function
. The heuristic helps to optimize an original function ![]() of
variables
of
variables ![]() , where
, where ![]() [Mockus et al., 1997]. As usual, components of
[Mockus et al., 1997]. As usual, components of
![]() are discrete variables. Heuristics are based on
expert opinions about the decision priorities. Now both DBA and BHA will
be considered in detail.
are discrete variables. Heuristics are based on
expert opinions about the decision priorities. Now both DBA and BHA will
be considered in detail.
 |
The Wiener model is extended to multidimensional case, too
[Mockus, 1989a]. However, simple approximate stochastic models
are preferable if ![]() . Approximate models are designed by
replacing the traditional Kolmogorov consistency conditions.
These conditions require the inversion of matrices of
. Approximate models are designed by
replacing the traditional Kolmogorov consistency conditions.
These conditions require the inversion of matrices of ![]() th order
for computing the conditional expectation
th order
for computing the conditional expectation ![]() and
variance
and
variance ![]()
![[*]](footnote.png) .
.
Replacing the regular consistency conditions by:
- continuity
of the risk function ![]()
- convergence of ![]() to the
global minimum
to the
global minimum
- simplicity of expressions of ![]() and
and
![]()
the following simple expression of ![]() is obtained
using the results of [Mockus, 1989a]
is obtained
using the results of [Mockus, 1989a]
The aim of DBA is to reduce the expected deviation. In addition, DBA has some good asymptotic properties, too. It is shown [Mockus, 1989a] that
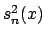
Note, that the correction parameter ![]() has a similar
influence as the temperature in simulated annealing. However,
that is a superficial similarity. The good asymptotic
behavior is just some "by-product" of DBA.
The reason is that Bayesian decisions are applied for small
size samples where asymptotic properties are not noticeable.
To choose the next point
has a similar
influence as the temperature in simulated annealing. However,
that is a superficial similarity. The good asymptotic
behavior is just some "by-product" of DBA.
The reason is that Bayesian decisions are applied for small
size samples where asymptotic properties are not noticeable.
To choose the next point ![]() by DBA, one
minimizes the expected deviation
by DBA, one
minimizes the expected deviation ![]() from the global optimum
(see Figure 1). The minimization of
from the global optimum
(see Figure 1). The minimization of ![]() is a complicated auxiliary optimization problem. That means that DBA is useful for expensive, in
terms of computing times, functions of a few (
is a complicated auxiliary optimization problem. That means that DBA is useful for expensive, in
terms of computing times, functions of a few (![]() )
continuous variables. This happens in wide variety of problems.
)
continuous variables. This happens in wide variety of problems.
Some examples are described in [Mockus, 1989a]. These include maximization of the yield of differential amplifiers, optimization of mechanical systems of a shock absorber, optimization of composite laminates, evaluation of parameters of immunological models and nonlinear time series, planning of extremal experiments on thermostable polymeric compositions. A large set of test problems in global optimization is considered in [Floudas et al., 1999].
procedures that depend on some
empirically defined parameters.
The examples of such parameters are:
- an initial temperature
of the simulated annealing,
- probabilities of different
randomization algorithms in their "mixture."
In these
problems DBA is a convenient tool for optimization of the
continuous parameters of various heuristic techniques and their
mixtures. That is the Bayesian Heuristic Approach (BHA)
[Mockus et al., 1997].
Applying DBA, the expert knowledge is involved by defining a prior distribution. In BHA one exploits expert knowledge "twice". First time one does that by defining the heuristics. Second time the expert knowledge is involved by defining a prior distribution, needed to optimize parameters of heuristics using DBA.
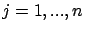
Here DBA is applied to optimize parameters ![]() of the auxiliary function
of the auxiliary function ![]() . This function
defines the best results obtained applying
. This function
defines the best results obtained applying ![]() times a
randomized heuristic algorithm
times a
randomized heuristic algorithm ![]() . That is the most
expensive operation of BHA. Therefore, the parallel computing
of
. That is the most
expensive operation of BHA. Therefore, the parallel computing
of
![]() should be used, if possible. Optimization
of
should be used, if possible. Optimization
of ![]() adapts the heuristic algorithm
adapts the heuristic algorithm ![]() to a given
problem. The
parameter
to a given
problem. The
parameter ![]() may be useful to solve related problems
[Mockus et al., 1997]. That helps
using the "on-line" optimization.
may be useful to solve related problems
[Mockus et al., 1997]. That helps
using the "on-line" optimization.
We illustrate the parameterization of ![]() by using
three randomization functions
by using
three randomization functions
![]() . Here the superscript
. Here the superscript ![]() denotes the uniformly
distributed component.
denotes the uniformly
distributed component. ![]() defines the linear component of
randomization. The superscript
defines the linear component of
randomization. The superscript ![]() denotes the pure
heuristics with no randomization. That means
denotes the pure
heuristics with no randomization. That means
![]() , if
, if
![]() and
and
![]() , otherwise. The
parameter
, otherwise. The
parameter
![]() defines probabilities of
using the randomizations
defines probabilities of
using the randomizations ![]() , correspondingly.
That can be understand as some "lottery of algorithms"
where
, correspondingly.
That can be understand as some "lottery of algorithms"
where ![]() is a probability to "win" the algorithm
is a probability to "win" the algorithm ![]() .
The detail description of
the knapsack example is in the next chapter.
.
The detail description of
the knapsack example is in the next chapter.
the best individual heuristics, as judged by examples. In addition, BHA provides almost sure convergence.
However, the results of BHA depend on the quality of specific
heuristics. The quality of heuristics reflects the expert knowledge. That means, BHA
should be considered as a tool for enhancing the heuristics but
not for replacing them.
Many well-known optimization algorithms, such as the Genetic Algorithms (GA) [Goldberg, 1989], GRASP [Mavridou et al., 1998], and the Tabu Search (TS) [Glover, 1994], may be considered as some general heuristics that can be improved using BHA. There are specific heuristics tailored to fit particular problems. For example, the Gupta heuristic was the best one while applying BHA to the flow-shop problem [Mockus et al., 1997].
The Genetic Algorithms [Goldberg, 1989] is an important "source" of interesting and useful stochastic search heuristics. It is well known [Androulakis and Venkatasubramanian, 1991] that results of the genetic algorithms depend on mutation and crossover parameters. The Bayesian Heuristic Approach could be used in optimizing those parameters.
In the GRASP system [Mavridou et al., 1998], a heuristic is repeated many times. During each iteration, a greedy randomized solution is constructed and the neighborhood around that solution is searched for the local optimum. The "greedy" component adds one element at a time, until a solution is constructed. A possible application of BHA in GRASP is in optimizing a random selection of a candidate to be in the solution. BHA might be useful as a local component, too, by randomizing the local decisions and optimizing the corresponding parameters.
In the Tabu search, two important parameters may be optimized using BHA. Those are:
