Subsections
16 Call Center Model
Call centers are important and rapidly developing commercial
activities. Call centers serve customers by phone, by fax and by
Internet.
There are different call centers depending on
their objectives and environments. However, investigating the
call centers one encounters three problems:
- modeling;
queuing systems are common tools while
modeling call centers,
- optimization;
one needs methods of stochastic and global
optimization are to optimize these systems,
- prediction; parameters, which are needed for modeling and optimization,
depends on predictions, predictions involve both the observed
data and the expert knowledge.
2 Assumptions,
Notations, and Objectives
One models call centers as queuing systems. The modeling system includes features for call rate predictions and service
optimization. One assumes that
- incoming calls are united into one stream with the call
rate
 , a call rate is the average number of calls in a
time unit,
, a call rate is the average number of calls in a
time unit,
- there are
 servers with the same service rate
servers with the same service rate
 , the service rate is the average number of calls that can
be served in a time unit,
, the service rate is the average number of calls that can
be served in a time unit,
- each server can serve any call,
one at a time,
- calls are Poisson with the
rate ,
- service times are exponential with the
rate
 , in such a case
, in such a case
where  is an average time between the calls and
is an average time between the calls and
 is an average service time,
is an average service time,
- arriving calls enter the first available server, if all the
servers are busy then the call takes a free waiting
place,
- there are
 waiting places,
that means that a call waits, if there are not more than
other calls waiting, otherwise, the call disappears,
waiting places,
that means that a call waits, if there are not more than
other calls waiting, otherwise, the call disappears,
- waiting places are common for all the calls
- the system is
stationary, meaning that the parameters and are
constant,
 is the server running cost ( $ per time
unit),
is the server running cost ( $ per time
unit),
 is the customer time cost ( $ per time
unit),
is the customer time cost ( $ per time
unit),
 is the lost customer cost ( $ per lost call),
is the lost customer cost ( $ per lost call),
- the optimal number of servers
 minimizes the
total cost
minimizes the
total cost 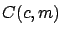
![[*]](footnote.png) per time unit, including the server running
cost, the customer time cost, and the lost customer cost at
fixed parameters and
per time unit, including the server running
cost, the customer time cost, and the lost customer cost at
fixed parameters and
 ,
,
- results are
presented as the waiting time distribution functions
 , where
, where
 is the probability that the waiting time
is the probability that the waiting time  will be
less than
will be
less than  at fixed number of servers and waiting places
,
at fixed number of servers and waiting places
,
- a family of functions
 is defined
for different parameters
is defined
for different parameters  , these functions are
presented in a simple format, assuming that the number of servers
is obtained by minimizing the total cost
, these functions are
presented in a simple format, assuming that the number of servers
is obtained by minimizing the total cost  .
.
2 Calculation of Stationary
Probabilities
Under these assumptions [Tijms, 1994], the probability of
 calls in the system, including both, waiting calls and calls
in services
calls in the system, including both, waiting calls and calls
in services
where
 . The no-calls probability
. The no-calls probability
follows from the condition
The probability of losing a call at given numbers
 is
is
The average waiting time
where
 is defined by expression (16.3)
and
is defined by expression (16.3)
and
 . The waiting time distribution
functions
. The waiting time distribution
functions
Here
 denotes the probability that waiting time
will exceed some fixed under condition that there
are calls
denotes the probability that waiting time
will exceed some fixed under condition that there
are calls
Here  is the probability that
is the probability that  calls will be served
during the time and
calls will be served
during the time and
If the number of waiting places is very large, one
considers asymptotic expressions (
 ) as a reasonable approximation. The asymptotic values are
denoted by the index
) as a reasonable approximation. The asymptotic values are
denoted by the index  . They are used to test
the software designed for finite . The
no-calls probability
. They are used to test
the software designed for finite . The
no-calls probability
The average waiting time
The waiting time distribution functions
Here
The asymptotic probability of losing a call is zero.
An incoming call gets a regular service
by an agent, if the actual or estimated waiting
time is less then  sec. Otherwise, a
call gets a "surrogate" service by voice-mail. For simplicity,
one replaces this service system by a
system with
sec. Otherwise, a
call gets a "surrogate" service by voice-mail. For simplicity,
one replaces this service system by a
system with
 , where the expected service time
is
, where the expected service time
is
 . Then one can use all the expressions for
the queuing system with waiting places.
Here, the call served by voice-mail is considered as the "lost"
call. One considers calls of different type
separately, because they are served by different agents.
. Then one can use all the expressions for
the queuing system with waiting places.
Here, the call served by voice-mail is considered as the "lost"
call. One considers calls of different type
separately, because they are served by different agents.
5 Call Rate Estimate
The lost calls are not registered, as usual. Therefore, it is
difficult to estimate the call rate directly, if is
limited. Then one uses least square estimates. The square
deviations
 between stationary
probabilities
between stationary
probabilities
 and their estimates
and their estimates  are minimized.
are minimized.
The stationary probabilities that there are calls in the
system are defined by expression
The least squares estimate of the call rate
The estimates are obtained by counting the numbers of
waiting calls at different time moments. Additional errors are
expected, if the average number of waiting calls in a time unit is counted, instead of moment numbers.
The total cost of a service system
One optimizes the server number by simple
comparison of different within reasonable bounds

7 Monte Carlo Simulation (MCS)
The explicit steady-state solutions
(16.6)-(16.13) are simple and exact, under the
assumptions. However, there is no general explicit solution, if
the call rate , and/or the service rate
depends on time. That often happens in real service systems.
The configuration and operating rules of real service systems
are too complicated for the exact solution, as usual.
Then the Monte Carlo Simulation (MCS) is needed. We start the
discussion of MCS from the steady-state systems keeping all the
assumptions described in Section 1.2. That helps to
test both the analytical and the Monte Carlo solutions by
comparing the results. Later, MCS is extended to more complicated
configurations and to time-dependent cases.
1 Event Generation
The events in a queuing system are the moments when a call
arrives, when a call enters a server, and when a call leaves the
system. To generate events, one needs two types of random number
generators. The first type generates times until the next call.
The second type generates service times.
Denote by
 the distribution function, where
the distribution function, where
 is the probability that a random time
will be less then . Here
is the probability that a random time
will be less then . Here  is the expected value of .
Denote by
is the expected value of .
Denote by ![$\xi \in [0,1]$](img85.gif) the random variable uniformly
distributed between zero and one. Then
the random variable uniformly
distributed between zero and one. Then
In exponential cases
Here  , if times until the next call are generated.
, if times until the next call are generated.
 , if service times are generated.
, if service times are generated.
The model defines moments when a call enters a server and leaves
the system. These moments depend on the specific structure of the
system. The model is designed trying
to represent the actual operations as realistically as possible.
However, the are limits that depend on the available computing power.
Here is a description of an algorithm of modeling and
optimization of call centers:
- denote by
 the "arriving" time of the
the "arriving" time of the  th call, then
th call, then
 , where
, where  is a random number, uniform in
is a random number, uniform in
![$[0,1]$](img129.gif) , and is the average number of calls in a time
unit, the moment of the first call moment
, and is the average number of calls in a time
unit, the moment of the first call moment  is the start
of MCS,
is the start
of MCS,
- denote by
 the "departing" time of th
call, then
the "departing" time of th
call, then
 , where
, where  is the average number of
calls which can be served in a time unit by all
is the average number of
calls which can be served in a time unit by all
 servers operating at the moment , thus
servers operating at the moment , thus
 , and is the average number of calls, served by single
server in a unit time,
, and is the average number of calls, served by single
server in a unit time,
- count all calls in the system at
the moment
 including those in servers and
waiting places by this expression
including those in servers and
waiting places by this expression
where  is the number of calls in the system at the moment
,
is the number of calls in the system at the moment
,
- define the number of servers
 operating at
the moment by this condition
operating at
the moment by this condition
- count calls lost up to the moment by the
expression
where  is the number of calls lost up to the the moment
,
is the number of calls lost up to the the moment
,
- count the waiting time by this counter
- count the number of calls
 that waited less than
that waited less than

- define the distribution of the call numbers that
waited less than
- define the optimal number of servers by simple
comparison of different within some reasonable bounds

- compare the results with the
corresponding steady-state explicit solutions, including the
average waiting time, the average of lost calls and the waiting
time distribution functions.
2 Monte Carlo Errors
Under independence conditions, the standard deviation
 of the results
of the results  of a statistical model
depends on the number of observations
of a statistical model
depends on the number of observations  as
as
Here  is the "initial" standard deviation
is the "initial" standard deviation
where
 and
and  is the expectation symbol.
is the expectation symbol.
In Monte Carlo simulation,  cannot be estimated
directly using the results
cannot be estimated
directly using the results  obtained by the 1-th
observation. Many observations are needed, to reach a stationary
state (one observation means one call). Therefore, we repeat the
Monte Carlo simulation
obtained by the 1-th
observation. Many observations are needed, to reach a stationary
state (one observation means one call). Therefore, we repeat the
Monte Carlo simulation  times doing observations each
time. Then the error variance can be estimated as
times doing observations each
time. Then the error variance can be estimated as
Expression (16.33) is simpler, if the exact solution
 is known . Then
is known . Then
Therefore, to test a Monte Carlo procedure, one considers a
model with exact solution, first. Then one applies MCS to more
complicated models.
3 Stopping Monte
Carlo
The Monte Carlo errors are important to define stopping rules.
The traditional idea is that the computing errors should not
be greater then the data gathering errors. In call centers, data
errors depend on the errors of call rate predictions, as usual.
Thus, the stopping rule is:
- stop at the first observation  satisfying this inequality:
satisfying this inequality:
Here  is a standard deviation of call rate predictions.
is a standard deviation of call rate predictions.
8 Common Waiting
The common waiting system is an example were one applies
approximate models, including the Monte Carlo. By common waiting
we define a system that serves calls of different type. One
represents them as a call-vector
 . Different calls are served
by different servers. However, there are
. Different calls are served
by different servers. However, there are  of common
waiting places. There are no simple formulas, such as
(16.16) and (16.15). Therefore, we consider
two approximate solutions: the analytical
"reservation" model, and the Monte Carlo one.
of common
waiting places. There are no simple formulas, such as
(16.16) and (16.15). Therefore, we consider
two approximate solutions: the analytical
"reservation" model, and the Monte Carlo one.
1 Analytical Approximation: Reservation
Model
One estimates
by minimizing
the square deviations
Here
 is the stationary
probability that there are
is the stationary
probability that there are  calls in the -th server. This
probability is defined by expressions similar to (16.3),
assuming that there are
calls in the -th server. This
probability is defined by expressions similar to (16.3),
assuming that there are  waiting places reserved for the
calls
waiting places reserved for the
calls  .
.
 is the reservation vector
and
is the reservation vector
and
 .
.
The estimates  are obtained by counting the numbers
of waiting -calls at different time moments. The least
square estimate of the call-vector is as follows
are obtained by counting the numbers
of waiting -calls at different time moments. The least
square estimate of the call-vector is as follows
The reservation model is simple and clear. However, one must test
the reservation assumption by the Monte Carlo model.
The statistical model can be used to estimate the call rates
in the same way as the analytical one. One estimates
by minimizing the square
deviations
 between the probabilities
and their estimates
between the probabilities
and their estimates
Here
 is the
probabilitythat there are calls in the -th server. The estimates are
obtained by counting the numbers of waiting -calls at
different time moments.
is the
probabilitythat there are calls in the -th server. The estimates are
obtained by counting the numbers of waiting -calls at
different time moments.
The least squares estimate of the
call-vector
The statistical model needs considerable computing
power.
The analytical approximation (see Chapter 8.1) is
simpler. However, it is based on the reservation assumption. The
statistical model may represent most of the important factors.
However, it takes a long time to "filter out" the random
deviations. In the on-line operations, this time is too long, as
usual.
To test analytical approximation, one compares
estimates of call rates
obtained by both the statistical and the reservation models. A
small deviation means that the reservation model is acceptable.
The large deviation means that the analytical approximation
should be improved.
9 Time-Dependant
Cases
Consider the MCS when the call rates
 ,
the number of servers
,
the number of servers  , and the number of waiting
places
, and the number of waiting
places  depend on time. Therefore, all the results
should be represented as functions of time. One modifies
algorithms, similar to those in the previous chapter, by
including the time factor:
depend on time. Therefore, all the results
should be represented as functions of time. One modifies
algorithms, similar to those in the previous chapter, by
including the time factor:
- denote by the "arriving" time of the th call, then
 , where is a random number uniform in
and is the average number of calls arriving in a time
unit that includes the moment ,
, where is a random number uniform in
and is the average number of calls arriving in a time
unit that includes the moment ,
- denote by the
"departing" time of th call, then
where is the average number of calls
which can be served in a time unit by all the
 servers operating at the moment , thus
and is the average number of calls served by
single server in unit time,
servers operating at the moment , thus
and is the average number of calls served by
single server in unit time,
- count the number of all the
calls in the system at the moment , including those in
 servers and
servers and  waiting places
waiting places
where is the number of calls in the system at the moment
,
- count the number of servers operating at the
moment
- count the number of calls lost up to the moment
where is the number of calls lost up to the the moment
,
- define the waiting time
- count the number of calls s that waited less than
- define the distribution of the call numbers that
waited less than
- optimize the number of servers
 at different times
by solving the corresponding stochastic scheduling
problem
at different times
by solving the corresponding stochastic scheduling
problem
- define the difference between the steady-state and dynamic
solutions by comparing the average results with the
corresponding steady-state explicit solutions, including the
waiting time distribution functions
, where
is the
probability that the waiting time will be less than ,
- define the iteration number
 by Monte Carlo
experimentation.
by Monte Carlo
experimentation.
Consider this simple example
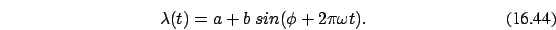
Here  and
and  . is caunted in
hours. is average number of calls in 24 hours.
. is caunted in
hours. is average number of calls in 24 hours.  is
amplitude of daily variation of calls,
is
amplitude of daily variation of calls,  .
.
One optimizes the numbers  and
and  of two different
servers considering two periods. This is a short description of
the optimization problem:
of two different
servers considering two periods. This is a short description of
the optimization problem:
- there are two optimization parameters and
restricted by bounds
 and
and
 ,
,
- one may obtain the
optimal pair by direct comparison of all the feasible pairs
- the total system cost is defined as
10 Call Rate Predictions
Consider ideas and models that supplement the ones
described in chapter 15. The call rate depends on
many factors (see Figures 16.1 and 16.2).
Therefore, one applies the extended version of the Auto-Regression-Moving-Average
(ARMA) model and software (see Chapter
15).
Figure 16.1:
A fragment of the the DATAFILE 'call.data' including the number, the date, the call rate (repeated twice) , the real-valued external factor (repeated twice) and the indicators of eight Boolean external factors.
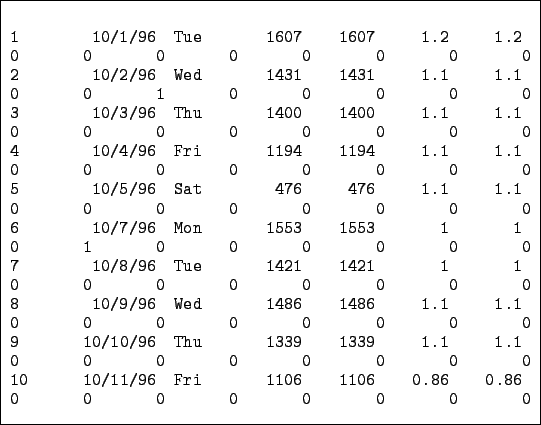 |
Figure 16.2:
Eight Boolean external factors related to call rate.
 |
The results show that one does not improve predictions by
including the external factors directly into the ARMA model. A reason is that in the ARMA
framework it is difficult to estimate the delay time (see
expression (15.22)) and the duration of impacts Special
Events (SE). The additional
difficulty is that most of SE are rare (see Figure
16.1). Therefore, columns of date file are filled
mostly by zeros. Most of the SE indicated in Figure
16.2 are predictable. For example, one can predict
factor 6 ( public holidays, traditional celebrations) and factor
7 (last day for ordering) exactly. Other SE can be predicted
approximately. The knowledge of future values of external
factors helps to predict the main one. However, the present software
version cannot use this possibility yet.
Here, we
consider call rates  as a sum of two stochastic
functions
as a sum of two stochastic
functions
Often the rate has several components
 corresponding to
different types of calls. In expression (16.48)
corresponding to
different types of calls. In expression (16.48)
 denotes a "stationary" component which is described by
the ARMA model. A "non-stationary" component is denoted by
denotes a "stationary" component which is described by
the ARMA model. A "non-stationary" component is denoted by
 . This way we separate the stationary part from the
non-stationary one.
. This way we separate the stationary part from the
non-stationary one.
The theoretical analysis of
non-stationary stochastic functions is difficult. Therefore, the
separation of non-stationary component is important. The
non-stationary component is defined by a local expert, as usual.
The expert applies his knowledge while using the previous data
and making the future predictions. Thus, we call as the
"expert" component and as the "statistical" one. The
estimate of the statistical component is investigated in
Chapter 15, considering the ARMA model. An alternative is "Scale" models. They predict the expert component
by estimated scales. The scales express the
differences between different SE and different times.
2 Call Rate Prediction by Scale Models
The ARMA models considered in Chapter 11 reflect
non-stationarity by eliminating unstable parameters applying the
structural stabilization techniques. This way some data and some
model parameters  are eliminated. The estimates of
the remaining ones are obtained. Therefore, one may regard ARMA
parameters as some scales, too. These scales reflect the
influence of the corresponding data sets by minimization of
prediction errors. No expert knowledge is involved.
are eliminated. The estimates of
the remaining ones are obtained. Therefore, one may regard ARMA
parameters as some scales, too. These scales reflect the
influence of the corresponding data sets by minimization of
prediction errors. No expert knowledge is involved.
Now we
shall consider the scale models, where the expert opinion is
involved. This is done by choosing data sets and scales reflecting the expert opinion. Two versions of scales models
are considered.
In the first model it is supposed that the
prediction  is a product of the present call rate
is a product of the present call rate  and some scale
and some scale 
Here is a predicted call rate, called a "prediction."
is an observed call rate, called a "data set." The
index  defines the data set used to predict . The
parameter is the "scale" to predict by
the data set . Expression (16.49) is a time
scale model. In this model the scale is estimated as
defines the data set used to predict . The
parameter is the "scale" to predict by
the data set . Expression (16.49) is a time
scale model. In this model the scale is estimated as
In (16.50) the subscript  defines a period
which precedes
defines a period
which precedes  . The subscript
. The subscript  denotes a period
preceding . The term "preceding" means the nearest previous
period of the same type. For example, Saturdays, Sundays,
holidays, Christmas weeks, sporting events, days of marketing
messages, e.t.c., all are different types.
denotes a period
preceding . The term "preceding" means the nearest previous
period of the same type. For example, Saturdays, Sundays,
holidays, Christmas weeks, sporting events, days of marketing
messages, e.t.c., all are different types.
In the second
model
Here the scale is estimated as
Both expressions(16.49) and (16.51) predicts the
same call rates. That means that one obtains the same results by
the event scales (16.50) and the time scales
(16.52). Only the interpretation differs.
In
the vector case, expressions (16.49) and (16.51)
predict different call rate graphs. One represents these graphs
as vectors
 . The components
. The components  denote call rates of different parts
denote call rates of different parts  of a period For
example, hours if we predict next day call rates.
of a period For
example, hours if we predict next day call rates.
The
assumption of the first model (16.49) is that the next
day graph
is equal to the present one
 multiplied by scales
multiplied by scales
Here
 denotes the average call rates
of the period . Expression (16.53) means that
the shapes of the next and the present graphs remains the
same. Only the scales differ.
denotes the average call rates
of the period . Expression (16.53) means that
the shapes of the next and the present graphs remains the
same. Only the scales differ.
The second model
(16.51) assumes that the next day graph is equal to the
graph of the preceding period
 multiplied by scales
multiplied by scales
This means that the shapes of the next graph and the preceding
one are the same. Only the scales differ. The numerator
 of scales of the first model depends on the
Special Events (SE) of the next period .
We call the first
model (16.49) as the event scale model.
of scales of the first model depends on the
Special Events (SE) of the next period .
We call the first
model (16.49) as the event scale model.
The numerator of scales of the
first model depends on the Special Events (SE) of the next
period . By definition, the preceding period depends
on the type of next one. The period type is defined by the
Special Event (SE) which is active in the period. Examples of
SE are Saturdays, Sundays, holidays, Christmas weeks, sporting
events, days of marketing messages e.t.c..
The numerator
 of scales
of scales  of the second model depends on
the average call rate now . Therefore, we call the second
model (16.51) as the time scale model.
of the second model depends on
the average call rate now . Therefore, we call the second
model (16.51) as the time scale model.
Using the event scale model (16.49),
the next day event SE defines the next day scale. The shape of
the next day graph remains the same as today. Therefore, this
model reflects the changes of the graph shapes without delay.
Using the time scale model (16.51), the shape of the
next day graph is the same as the shape of the preceding one.
Here the graph changes, but with some delay. The interval between
the next period and the previous period of the same type defines
the delay time.
1 Definition of Special Events
Here the call rate in the next period (16.49) is
the same as in the present one multiplied by the
scale . The scale depends on the Special Event (SE) which
is expected to be active in the next period. The periods where
no special events are active, we consider as periods with
"neutral" special events. Scales determine the impact of
SE to the call rate of next period.
The scale
reflecting the impact of a special event is estimated
using empirical data by expressions (16.50),
(16.53) and/or directly by expert opinions.
The
impact of some special events, such as Saturdays, Sundays,
holidays, Christmas week e.t.c.. is well defined and instant. One calls them Instant Special Events (ISE).
The impact
of some others, such as marketing messages, is delayed. Call
rates react to these events with some delay. Therefore, one calls them
Delay Special Events (DSE). The starts and the durations of
DSE are fixed. The delay times  and the durations of
DSE impacts are estimated using the observed data and expert
knowledge. In some periods several DSE may be active
simultaneously. One calls these Multiple Special
Event (MSE).
and the durations of
DSE impacts are estimated using the observed data and expert
knowledge. In some periods several DSE may be active
simultaneously. One calls these Multiple Special
Event (MSE).
The starts and the durations of ISE and
their impacts are equal to starts and durations of the corresponding
periods. Beginnings and durations of DSE impacts are not
necessarily equal to the beginnings and durations of the periods.
Therefore, a special sorts of DSE appear, called Partial Special
Events (PSE). In PSE the impact of a special event is active
only during some part of the period. The delay times , the
durations of the impacts of DSE, and the scales
defining the impact of all the special events, are estimated using
the available data and the expert knowledge.
We consider three expert procedures and the method of
least squares, while defining estimates of scales .
The first procedure is the empirical one. The
scales describing the impact of all sorts of events,
including the partial and the multiple ones, are estimated by
expressions (16.50) or (16.53). These
expressions define the relation of the call rates in the pair
of periods and . A period precedes
the present period . Denote by a period that
precedes the next one, denoted . The numerator  is the call
rate of the period preceding the next one. The
denominator
is the call
rate of the period preceding the next one. The
denominator  is the call rate of the period
preceding the present one.
is the call rate of the period
preceding the present one.
Using the empirical
procedure, partial and multiple special events are considered
as different SE. Here scales are defined separately for
each of them. Therefore, the empirical procedure is convenient,
if the data is available for all types of periods, including the
partial and multiple ones. In such a case, estimate of the
delays and durations of DSE is not needed. It is
supposed that an identical situationis in the available data. One needs large data sets for that.
The second direct procedure is the subjective one. All
unknown parameters of the expert model, such as the scales ,
the delay times and the duration times , are defined
by the expert opinion. This is a reasonable way to start a new
system, when no data is available.
The third direct
procedure is a mixture of the empirical and the subjective ones.
We use empirical estimates, if the corresponding data is
available. Otherwise, one
uses subjective estimates. Using the method of least
squares, we search for such scales , such delay and duration
times  that minimize the sum of squared deviations. The
deviations are differences between the call rates predicted by
the expert model and the observed call rates .
All four procedures are applied to different times: hours, days,
weeks and seasons. First, we consider the scalar case.
that minimize the sum of squared deviations. The
deviations are differences between the call rates predicted by
the expert model and the observed call rates .
All four procedures are applied to different times: hours, days,
weeks and seasons. First, we consider the scalar case.
3 Scalar Prediction
In the scalar case, one predicts a single number, the average call
rate of the next period. In the formal terms, one considers
the call rate function as a sample of some non-stationary
stochastic process. Four different periods; hours, days, weeks,
and seasons, are considered independently. Let us start by
describing hours.
Using the event scale model, a call rate of the next
hour is expressed this way
Here is the present call rate. is a scale of the
next hour . The hourly scales differ depending on the
impact of SE felt at the day . For example, working days,
weekends, Christmas days, marketing messages days, e.t.c.
Here is a subscript of the hour preceding the next
one. is a subscript of the hour preceding the
present one. Following examples illustrate what one means by
the term "preceding."
2 Examples of Multiple
Special Events (MSE)
Suppose that the impact of the special event "marketing
messages send" starts at the next hour
, that is the second one of a working day. Assume that the
present hour is the first one of a working day. Then
Here is the subscript of the most recent previous second
hour of a working day with the same impact SE. is the
subscript of the most recent previous first hour of a working
day with no SE. In this example, we consider a multiple SE as two
single SE. The first single SE means the first working hour
without the impact of marketing messages. The second single SE
defines the second working hour with the impact of marketing
messages.
Another way is to consider the impacts of those
two SE separately. Then one defines the scale as a product
of two scales
Here
where  is the index of the first hour and
is the index of the first hour and  is the index of the second hour. Both indices denote the previous
working day.
is the index of the second hour. Both indices denote the previous
working day.
where  is the index of the most recent hour with
"marketing" and is the index the most recent hour with no
"marketing." Expression (16.58) needs less data.
However, it is based on the assumption that scales are
multiplicative. Expression (16.58) involves expert
opinion by assuming multiplicativity of scales. Expression (16.57) is an example of
empirical approach; multiple SE are considered as different
special events.
is the index of the most recent hour with
"marketing" and is the index the most recent hour with no
"marketing." Expression (16.58) needs less data.
However, it is based on the assumption that scales are
multiplicative. Expression (16.58) involves expert
opinion by assuming multiplicativity of scales. Expression (16.57) is an example of
empirical approach; multiple SE are considered as different
special events.
3 Examples of Partial Special Events
(PSE)
The only difference from the previous example is that the
impact of "marketing messages" starts at the 20-th minute of the
next hour . Supose that PSE is a special sort of SE with the
scale
Here is the subscript of the most recent previous day
when the "marketing" starts at the 20-th minute of second
working hour. is the subscript of the most recent
previous first hour of a working day with no marketing.
Another way is to consider the impact of PSE by setting the
scale of marketing messages, in proportion to the duration
of their impact
where
Here is the subscript of the most recent previous day
when the "marketing" starts at the second working hour.
is the subscript of the most recent previous first hour
of a working day with no marketing.
Expression
(16.62) needs less data. However, it is based on the
assumption that scales are proportional to the impact duration. Expression
(16.62) involves expert opinion by assuming the
proportionality of scales.
Expression (16.61) is an example of the empirical approach
where a PSE is considered as a different special event.
Denote by
 the call rate prediction by an
expert model with fixed parameters
the call rate prediction by an
expert model with fixed parameters  . One predicts call
rates of the next period , using data up to the period .
The parameters of the model include scales and delay and
duration times
. One predicts call
rates of the next period , using data up to the period .
The parameters of the model include scales and delay and
duration times  . We minimize the sum
. We minimize the sum
Here  is the end and
is the end and  is the beginning of the "learning"
set.
is the beginning of the "learning"
set.
One minimizes (16.64) by
various global and local optimization methods. That means that
estimates of parameters of expert scale models are obtained in
the same way as estimates of ARMA parameters (see Section
15). The difference of (16.64), is that parameters of the
expert model EM are optimized, instead of ARMA parameters . The optimization problem (16.64)
is very difficult. Here, the number of variables is great and
the objective function is multi-modal.
5 Vector Prediction, Event Scale
Version
One often predicts the graph of call rates of the next perid. The
graph is represented as call rates of different parts of the
next period. These call rates are components of some
vector. That justifies the term "vector prediction".
The only
difference from the scalar prediction is that we predict not a
single call rate of the next period , but some vector
. Here the component
definines the call rate of the part of the period .
First, we consider daily predictions, where index denotes
days and the index denotes hours.
1 Daily
Vector Prediction
We predict the hourly call rates for the next day. The
predicted call rate of the hour of the day is
Here  is the call rate of the hour of the present
day .
is the call rate of the hour of the present
day .  is a scale of the next day . The scales
depend on the impact of SE felt at the day . For
example, working day, Saturday, Sunday, Christmas day,
marketing day, e.t.c.
is a scale of the next day . The scales
depend on the impact of SE felt at the day . For
example, working day, Saturday, Sunday, Christmas day,
marketing day, e.t.c.
Denote by the subscript of the nearest previous day,
similar to the next one. Denote by the subscript of
the nearest previous day, similar to the present one. The
meaning of "nearest previous day similar to" is illustrated by
following examples.
Suppose that the impact of the SE "marketing messages send"
starts at the next day . That is Tuesday. The present day
is Monday with no additional special events. Then the scale
Here is the subscript of the most recent previous Tuesday
with the same SE. is the subscript of the most recent
previous Monday with no SE. In this example we considered a
multiple SE as two single SE: Monday without marketing, and
Tuesday with marketing.
Another way is to consider the
impacts of those two SE by defining the scale as a product
of two scales.
Here
where is the index of Monday, is the index
of Tuesday of the previous week, and
is the index of the most recent day with
"marketing." Index denotes the most recent day with
no "marketing." Expression (16.67) is an example of
empirical approach. Here multiple SE are regarded as different
special events. Expression (16.68) needs less data but
is based on an expert assumption that scales are multiplicative.
One feels the impact of the special event, called "marketing,"
next day on the sixth working hour. That is the only
difference from the previous example. Let us to consider PSE as
another SE. Then
Here is the subscript of the most recent previous week
when the "marketing" starts Tuesday at the sixth working hour.
is the subscript of the most recent previous Monday with
no marketing.
Another way is to regard PSE as a reduced
SE. Then, the scale is proportional to the impact duration
Here
is the subscript of the most recent previous week, such
that "marketing" starts Tuesday on the sixth hour, and
is the subscript of the most recent previous Monday with
no marketing.
Expression (16.71) is an example
of empirical approach when a PSE is regarded as a different
special event. Expression (16.72) needs less data.
However, it is based on an expert assumption that scales are
proportional to the impact duration.
Denote by
 the call rate prediction by an
expert model with fixed parameters . One predicts call
rates of the part of the next period using data up to the
period . The parameters of the expert model include scales
and delay and duration times . All special events,
including DSE and PSE, are regarded. We minimize the sum
the call rate prediction by an
expert model with fixed parameters . One predicts call
rates of the part of the next period using data up to the
period . The parameters of the expert model include scales
and delay and duration times . All special events,
including DSE and PSE, are regarded. We minimize the sum
Here is the end and is the beginning of the "learning"
set.
Define the expression (16.74) as a function 'fi'
in the file 'fi.C'. Then one minimizes (16.74) by
various global and local optimization methods. That means that
estimates of parameters of expert scale models are obtained in
the same way as estimates of ARMA parameters (see Section
15).
Scalar predictions by time scales are identical to those
using event scales. Vector predictions by time scale models
(16.51) are different from those using event scale models
(16.49). Here the shape
 of the
next day graph remains the same as that on the preceding day
. Only scales
of the
next day graph remains the same as that on the preceding day
. Only scales  change. This
follows from (16.52). Scales of the
present period reflect changes of average call rates
between the present period and the preceding one. The scales are
estimated using empirical data and/or expert opinion. The
definitions and examples of all the special events are the same
as in the Event Scale case (see Section 10.3).
We shall consider four procedures to obtain estimates: empirical, subjective, mixed,
and least squares. The estimates are similar to those in the
Event Scale Model (see Section 10.3). Only scales and
preceding periods are different. One predicts a vector
. Here
means the call rate of the part of the period . First, we
consider daily predictions. Then the index denotes days, and the
index denotes hours.
change. This
follows from (16.52). Scales of the
present period reflect changes of average call rates
between the present period and the preceding one. The scales are
estimated using empirical data and/or expert opinion. The
definitions and examples of all the special events are the same
as in the Event Scale case (see Section 10.3).
We shall consider four procedures to obtain estimates: empirical, subjective, mixed,
and least squares. The estimates are similar to those in the
Event Scale Model (see Section 10.3). Only scales and
preceding periods are different. One predicts a vector
. Here
means the call rate of the part of the period . First, we
consider daily predictions. Then the index denotes days, and the
index denotes hours.
We predict the hourly call rates of the next day. The predicted
call rate of the hour of the next day is
Here  is the call rate of the hour of the day
preceding the next one. is a scale of today .
Scales depend on the impact of SE felt at the day
. For example, working day, Saturday, Sunday, Christmas day,
marketing day, e.t.c.
is the call rate of the hour of the day
preceding the next one. is a scale of today .
Scales depend on the impact of SE felt at the day
. For example, working day, Saturday, Sunday, Christmas day,
marketing day, e.t.c.
Here is a subscript of the day preceding the present
one. The term "preceding" is illustrated by the following
examples.
Suppose that the impact of the SE "marketing messages send"
begins and ends today , which is Monday. The next day is
Tuesday with no additional special events. Then the scale
The index denotes the day, which precedes the present
one. Here, we regard a multiple SE as two single SE. First
single SE is Monday with marketing. The second single SE is
Tuesday without marketing.
Another way is to regard the
impacts of those two SE by defining a scale as a
product of two scales.
Here
is the index of the day preceding Monday without
marketing.  is the index of the day preceding
.
is the index of the day preceding
.
 is the index of the day preceding the day with
marketing.
is the index of the day preceding the day with
marketing.  is the index of the day preceding
.
is the index of the day preceding
.
Expression (16.77) is an example of
empirical approach when multiple SE are regarded as different
special events. Expression (16.78) needs less data but
is based on the assumption that scales are multiplicative.
Here, the impact of "marketing" starts at the second working
hour of the present Monday . Regarding PSE as another
SE the scale is
Here is the index of the day preceding the present one.
Another way is to regard the PSE as a reduced SE. Then
the scale is proportional to the impact duration
Here
 is the index of the preceding marketing Monday.
is the index of the preceding marketing Monday.
 is the index of the day preceding .
Applying expression (16.82) one requires less data.
However, this expression is based on the assumption that scales
are proportional to the impact duration.
is the index of the day preceding .
Applying expression (16.82) one requires less data.
However, this expression is based on the assumption that scales
are proportional to the impact duration.
Expression
(16.82) involves expert opinion indirectly, by assuming
proportional scales. Expression (16.81) is an
example of empirical approach when a PSE is regarded as another
SE.
Denote by
the call rate prediction by an
expert model with fixed parameters . One predicts call
rates of the part of the next period using data up to the
period . The parameters of the expert model include scales
and delay and duration times . All special events,
including DSE and PSE are regarded. We minimize the sum
Here is the end and is the beginning of the "learning"
set.
One minimizes (16.64) by
corresponding global and local optimization methods.
As usual, expert models predict the weekly and the seasonal graphs. The weekly graphs are given in a form of average calls for each of seven days. In the seasonal graphs, weeks are represented by weekly averages. Often "observed" values of the call rates
cannot be defined directly. Then their estimates are used (see
Section 5). Missing or uncertain data is
replaced by expert estimates. This is important for the first
year of operation.
Here we consider how to apply the ARMA model to
predict the errors  of the expert scale model
, where
of the expert scale model
, where
 [Mockus et al., 1997]. The formal description of the ARMA model is in
Chapter 15. The software is on the web-site (see
Section 4).
If predicting we do not know
some values of
[Mockus et al., 1997]. The formal description of the ARMA model is in
Chapter 15. The software is on the web-site (see
Section 4).
If predicting we do not know
some values of
 then we replace the
missing data by the expected values of the unknown
then we replace the
missing data by the expected values of the unknown  defined recurrently (see Section 10).
defined recurrently (see Section 10).
ARMA models predict only the difference between the expert
models (EM) and the data. Therefore, in the first step, EM
models are adapted to the data by defining the right scales. Only
then, the parameters  of ARMA models are optimized. This
means that one minimizes a squared difference between the adapted
EM model and the observed data. Predicting the data, the results
of both EM and AH models are summed up.
of ARMA models are optimized. This
means that one minimizes a squared difference between the adapted
EM model and the observed data. Predicting the data, the results
of both EM and AH models are summed up.
The vector prediction of EM errors is performed using
multi-step ARMA predictions described in Section 10
"Confidence cones" could be useful for preliminary evaluation of
prediction errors. They estimate probable deviations from
expected values with some "confidence level," say ninety percent or
ninety nine percent. These cones are defined empirically as upper and
lower limits of the results obtained by repetition of Monte
Carlo procedures (see Section 10).
In the call center example, both the Expert and ARMA models were
tested separately. Figure
15.18 shows daily call rates of this center. Table
15.1 illustrates some results of the ARMA model. Results
of the expert model are not available, for publication.
11 Call Center Scheduling
There are "Of-the-Shelf" tools for the scheduling of single-skill
agents. The scheduling of multi-skill agents is theoretically
possible using Monte Carlo simulation (see Section
7). However, the simulation time is too
large for on-line scheduling. A convenient approximation to
multi-skill scheduling is the reduction of multi-skill problems
to the single-skill ones. One can do that by representing each
multi-skill agent as a "weighted" single-skill one
Then, one estimates the unknown weight  by minimizing the
sum of squared deviations. The deviations are differences
between results of approximate single-skill model and the
multi-skill one
by minimizing the
sum of squared deviations. The deviations are differences
between results of approximate single-skill model and the
multi-skill one
Here  denotes the results of the iteration of a Monte
Carlo simulation of the multi-skill system. is the call
rate.
denotes the results of the iteration of a Monte
Carlo simulation of the multi-skill system. is the call
rate.  is the number of multi-skill agents.
is the number of multi-skill agents.  is the
result of the iteration of a Monte Carlo simulation of a
single-skill system.
is the
result of the iteration of a Monte Carlo simulation of a
single-skill system.  is the number of single-skill
agents, which replace the multi-skill ones.
is the number of single-skill
agents, which replace the multi-skill ones.
Another way
is to extend the single-skill simulation (see Section
11) to the multi-skill case. Here one needs more
computing time to estimate the "optimal" weights for
different call rates. For example, the method  is used
to obtain the best values of (see Section 4).
is used
to obtain the best values of (see Section 4).
There are two immlementations of the ARMA model,
both are on the web-sites n the "Software Systems".
The Java version is marked as  ,
the C++ version is denoted by
,
the C++ version is denoted by  .
.
To start the program [Jankauskas, 2000], one goes to one of web-sites
(see Section 4) and selects the problem "Call Center-SCALES-GMJ" in the section "Global Optimization ".
Figure 16.3 shows the operating page.
Figure 16.3:
Operating page.
 |
Here is an illustrative example of data file.

jonas mockus
2004-03-20































