Next: 16 CALL CENTERS Up: 3 EXAMPLES OF MODELS Previous: 14 INVESTMENT PROBLEM Contents Index
Mainly, the financial data is predicted. The prediction of call rates, using the same models, are briefly mentioned, just for comparison. The call rate prediction is described in detail considering call center optimization problems in Chapter 16. There the traditional ARMA is supplemented by an expert model.
Modeling economic and financial time series by ARMA has attracted the attention of many researchers in recent years [Diebold and Rudebusch, 1989,Cheung, 1993,Yin-Wong and Lai., 1993,Cheung and Lai, 1993,Koop et al., 1994,Mockus and Soofi, 1995]. Three approaches have been used to estimate the parameters of the ARMA models, : Maximum Likelihood (ML) [Sowel, 1992], approximate ML [Li and McLeod, 1986,Fox and Taqqu, 1986,Hosking, 1981,Hosking, 1984], and two-step procedures [Geweke and Porter-Hudak, 1983,Janacek, 1982]. In all the cases local optimization techniques were applied. Here the optimization results depend on the initial values, what implies that one cannot be sure if the global maximum is found.
The
global optimization is very difficult in many cases![[*]](footnote.png) . The reason is a high
complexity of multi-modal optimization problems. It is well known
[Ko, 1991] that optimization of polynomial-time computable real functions cannot be done in
polynomial-time, unless
. The reason is a high
complexity of multi-modal optimization problems. It is well known
[Ko, 1991] that optimization of polynomial-time computable real functions cannot be done in
polynomial-time, unless ![]() . In practice, this means that we need an
algorithm of exponential time to obtain the
. In practice, this means that we need an
algorithm of exponential time to obtain the ![]() -exact
solution. The number of operations in exponential algorithms
grows exponentially with the accuracy
-exact
solution. The number of operations in exponential algorithms
grows exponentially with the accuracy ![]() of solution and dimension
of solution and dimension ![]() of the optimization problem. The accuracy
of the optimization problem. The accuracy ![]() means that
means that
![]() . The dimension
. The dimension ![]() means that one optimizes a function
means that one optimizes a function ![]() where
where
![]() .
.
The Least Squares (LS) method is a popular approach to
estimate parameters of ARMA models.
Using LS one minimizes the log-sum of square residuals using ARMA models
and their extensions [Mockus and Soofi, 1995]. In this chapter, the
multi-modality problems are considered using different data. The
data include:
daily exchange rates of $/£ and DM/$ ,
closing rates of stocks of AT&T , Intel Co, and some Lithuanian
banks,
the London stock exchange index [Raudys and Mockus, 1999],
call-rates of a commercial call-center.
The graphical images
and comparison of the average prediction results of ARMA and
the Random Walk (RW) models are presented.
| $/ |
- 1.779090e-01 | 1.293609e+00 | 8.454827e-02 |
| DM/$ | - 1.191e-02 | 1.092e-01 | 9.985e-02 |
| Yen/$ | - 1.086e+00 | 6.369e+00 | 6.446505e+00 |
| Fr/$ | - 3.029e-01 | 4.285e-01 | 3.395e-01 |
| AT&T | -1.375e+00 | 4.554e+00 | 3.621e+00 |
| Intel Co | +2.814e-01 | 2.052e+01 | 1.936e+00 |
| Hermis Bank | -4.280e+01 | 2.374e+01 | 1.998e+01 |
| London Stock Exchange | -5.107e-01 | 2.751e+02 | 2.346e+01 |
| Call Center | +3.076e+01 | 8.453e+02 | 7.111e+02 |
The data is divided into three
equal parts.
The first part is to estimate parameters
![]() and
and ![]() of an ARMA model using fixed numbers
of an ARMA model using fixed numbers ![]() and
and
![]() .
.
The best values of ![]() and
and ![]() are defined using the
second part of data.
are defined using the
second part of data.
The third part is to compare ARMA and RW
models. The table shows the comparison results.
Table 15.1 shows that the ARMA model predicts all the financial data not better than RW. However, ARMA predicts call rates thirty one percent better then RW. That is a statistically significant difference. The observed deviations between RW and ARMA models of financial data are too small for practical conclusions.
Figure 15.1 shows optimal parameters
the model should be modified accordingly.
Different
symbols are used in ARMA models with external factors.
The predicted value is denoted by ![]() and the external
factors are
and the external
factors are
![]() . An influence of
some external factors may be delayed.
. An influence of
some external factors may be delayed.
For illustration,
consider two-dimensional case, omitting the Moving Average (MA)
part. This means the two-dimensional Auto Regressive (AR) model
with an external factor ![]()
Sum
(15.25), as a function of delay parameter ![]() , is not
necessarily uni-modal one. Thus to define the exact minimum
, is not
necessarily uni-modal one. Thus to define the exact minimum
This algorithm is to "fill" the missing
data only for the predicted factor ![]() . We replace missing
values of the external factor
. We replace missing
values of the external factor ![]() by the nearest previous
value, because we do not predict the external factors in this
model.
by the nearest previous
value, because we do not predict the external factors in this
model.
Applying AR-ABS models to external factors is similar to that of ARMA models described in Section 5. One just omits the MA parameters ![]() . Then, from (15.29) one can write
. Then, from (15.29) one can write
AR models with external factors
can be applied to estimate Linear Regression parameters, too.
The difference of LR models from those of AR is that in the former
case ![]() denotes the test number. It is supposed that the observed values
of the main parameter
denotes the test number. It is supposed that the observed values
of the main parameter ![]() and external
parameters
and external
parameters
![]() at different tests
at different tests ![]() and
and ![]() are independent.
For example the diagnosis
are independent.
For example the diagnosis ![]() of some patient
of some patient ![]() does not
depend on the health of others patients
does not
depend on the health of others patients ![]() .
In such a case the "memory"
.
In such a case the "memory" ![]() and
and expression (15.39) is modified this way
and
and expression (15.39) is modified this way
Let us to represent the multi-factorial LR model (15.41) by one-dimensional time series of the special type
One see from expression (15.46) that
residuals ![]() are non-linear functions of parameters
are non-linear functions of parameters
![]() . This means that
the minimum conditions
. This means that
the minimum conditions
An interesting activation function is derived using the Gaussian distribution function
but is convenient for analysis.
Here sum (15.46) depends on the parameters
In the traditional ANN models the activation functions are selected by their resemblance to the natural ones from biophysical experimentation. In this research the resemblance factor is neglected. The activation function (15.49) is considered just as a reasonable non-linearity that should be adapted to the available data. The multi-modality problems of ANN models are discussed in [Mockus et al., 1997].
We define an ARFIMA process as the following
time series ![]()
The logarithm is used to decrease the objective
variation by improving the scales. The objective ![]() depends
on
depends
on ![]() unknown parameters. They are represented as an
unknown parameters. They are represented as an
![]() -dimensional vector
-dimensional vector
![]() .
.
It follows from (15.59),
(15.54), and (15.52) that residuals
![]() are linear functions of the parameters
are linear functions of the parameters ![]() . This
means that the minimum conditions
. This
means that the minimum conditions
The system
The equation
The objective ![]() is a
multi modal function of parameters
is a
multi modal function of parameters ![]() and
and
![]() . Therefore, one uses methods of
global optimization (see, [Mockus et al., 1997]). Denote
. Therefore, one uses methods of
global optimization (see, [Mockus et al., 1997]). Denote
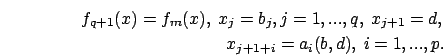
There is no variance ![]() in expressions
(15.64) and (15.59). If necessary,
we have to estimate the variance by another well-known technique.
in expressions
(15.64) and (15.59). If necessary,
we have to estimate the variance by another well-known technique.
|
|
||||
| $/ |
-1.195 | -0.169 | 0.0005 | 1.51675 |
| DM/$ | -1.019 | 0.0120 | 0.0007 | 1.60065 |
| AT&T | -1.017 | 0.0118 | 0.00005 | 9.83208 |
| Intel Co | 0.9975 | 0.0055 | 0.012 | 7.35681 |
 |
This apparent contradiction
may be resolved by dropping the assumption that the parameters
![]() of the ARFIMA model remain constant. This assumption is
common for most of the traditional methods. An alternative is the
structural stabilization model described in Chapter
11.
of the ARFIMA model remain constant. This assumption is
common for most of the traditional methods. An alternative is the
structural stabilization model described in Chapter
11.
The
illustration is in Figure 15.2.
The line
![]() shows the observed call rate. Lines
shows the observed call rate. Lines
![]() ,
,
![]() , and
, and ![]() show the
minimal, the average, and the maximal results of MSP predictions.
The "min" and "max" lines denote the lower and the upper values
of simulation. Therefore, these lines are called "MSP-
confidence intervals," meaning that if the model is true, one
may expect those "intervals" to cover the real data with some
"MSP-confidence level"
show the
minimal, the average, and the maximal results of MSP predictions.
The "min" and "max" lines denote the lower and the upper values
of simulation. Therefore, these lines are called "MSP-
confidence intervals," meaning that if the model is true, one
may expect those "intervals" to cover the real data with some
"MSP-confidence level" ![]() .
.
It is difficult to
define ![]() exactly. If "interval deviations" may be
considered as independent and uniformly distributed random
variables, we obtain
exactly. If "interval deviations" may be
considered as independent and uniformly distributed random
variables, we obtain
![]() . Here
. Here ![]() is the number of
Monte-Carlo repetitions. In the example,
is the number of
Monte-Carlo repetitions. In the example, ![]() , thus
, thus
![]() .
.
This assumption over-simplifies the
statistical model. Therefore, the "MSP-confidence
level" ![]() is just a Monte Carlo approximation.
is just a Monte Carlo approximation.
The objective of traditional time series models is
to define such parameters that minimize a deviation from the
available data. One may call them as the best fit models. The
goodness of fit is described by continuous parameters ![]() called
as state variables. For example, in the ARMA model (see
expression (15.1)) the state variables are
called
as state variables. For example, in the ARMA model (see
expression (15.1)) the state variables are
![]() .
.
If the parameters remain constant, then models that fit best to the past data will predict the future data as well. Otherwise, the best fit to the past data can be irrelevant or even harmful for predictions. Therefore, one needs models which are not sensitive to the changes of parameters. Such models may predict the uncertain future better by eliminating the nuisance parts from the structure of the model.
Trying to solve this problem, one introduces a notion of the
model structure. The model structure is determined by the
Boolean parameters ![]() called as structural variables. A
structural variable is equal to unit, if the corresponding
component of time series model is included. Otherwise, the
structural variable is equal to zero.
called as structural variables. A
structural variable is equal to unit, if the corresponding
component of time series model is included. Otherwise, the
structural variable is equal to zero.
For example, in the ARMA
model
![]() . Here
. Here
![]() , if the parameter
, if the parameter ![]() is included into the ARMA model.
Otherwise,
is included into the ARMA model.
Otherwise, ![]() . We search for such structure
. We search for such structure ![]() of the model that
minimizes the prediction errors in the changing environment.
To achieve this we divide available data
of the model that
minimizes the prediction errors in the changing environment.
To achieve this we divide available data
![]() into two parts
into two parts
![]() and
and
![]() .
.
The first part ![]() is to estimate
continuous parameters
is to estimate
continuous parameters ![]() that depends on Boolean structural
parameters
that depends on Boolean structural
parameters ![]() . The estimates are obtained for a set of all feasible
. The estimates are obtained for a set of all feasible
![]() by minimizing the least square deviation using data
by minimizing the least square deviation using data ![]() .
.
The second part
![]() is used to select such
is used to select such ![]() that minimize the least square
deviation. This means that the second part
that minimize the least square
deviation. This means that the second part ![]() is to
estimate Boolean structural parameters.
is to
estimate Boolean structural parameters.
Denote by
![]() the predicted value of a model
the predicted value of a model ![]() with fixed
parameters
with fixed
parameters ![]() using the data
using the data
![]() . The
difference between the prediction and the actual data
. The
difference between the prediction and the actual data ![]() is
denoted by
is
denoted by
![]() . Denote by
. Denote by ![]() the fitting parameters
the fitting parameters ![]() which minimize the sum of squared
deviations
which minimize the sum of squared
deviations
![]() using the first data set
using the first data set ![]() at
fixed structure parameters
at
fixed structure parameters ![]() .
.
parameters and parts of
the time series.
We consider two data sets ![]() and
and ![]() just for simplicity. One may partition the data
just for simplicity. One may partition the data ![]() into many data
subsets
into many data
subsets
![]() . In this case we minimize the sum
. In this case we minimize the sum
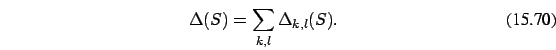
The idea of the structural stabilization
follows from the following observation. The best estimate of time
series parameters, using a part ![]() of the data
of the data
![]() , is optimal for another part
, is optimal for another part ![]() only if all the
parameters remain the same. Otherwise, one may obtain a better
estimate by elimination of the changing parameters from the model. For
example, in the case of changing parameters
only if all the
parameters remain the same. Otherwise, one may obtain a better
estimate by elimination of the changing parameters from the model. For
example, in the case of changing parameters
![]() of the ARMA model, the best prediction is
obtained by elimination of all these parameters, except
of the ARMA model, the best prediction is
obtained by elimination of all these parameters, except ![]() (see
Table 15.1).
(see
Table 15.1).
.
Assume that
unknown parameters depend on ![]() this way
this way

The best prediction ![]() is provided
by the structure
is provided
by the structure ![]() . The reason is obvious: this
structure eliminates the highly unstable parameter
. The reason is obvious: this
structure eliminates the highly unstable parameter ![]() .
Applying the structural stabilization one eliminates the nuisance
parameter
.
Applying the structural stabilization one eliminates the nuisance
parameter ![]() and simplifies AR model (15.72)
and simplifies AR model (15.72)
Various examples of structural optimization are described in [Mockus, 1997]. Here the structural optimization is considered in time series models with external factors.
If predictions depend on several factors, the
multi-dimensional ARMA should be used. Denote by
![]() the main statistical component and by
the main statistical component and by
![]() the external factors. One extends the
traditional ARMA model this way
the external factors. One extends the
traditional ARMA model this way
One minimizes the squared deviation at fixed structural
variables ![]()
If ![]() is fixed, the optimal values of
is fixed, the optimal values of
![]() are defined by a system of linear equations. These
equations follows from the condition that all the partial
derivatives of sum (15.75) are equal to zero
are defined by a system of linear equations. These
equations follows from the condition that all the partial
derivatives of sum (15.75) are equal to zero
![]() .
Therefore, to obtain the least
squares estimates
.
Therefore, to obtain the least
squares estimates
![]() at given
at given ![]() one solves
one solves ![]() linear equations with
linear equations with ![]() variables
variables
![]() (see Chapter 3 for details).
(see Chapter 3 for details).
To optimize discrete structural
variables ![]() one uses another data set. It starts at
one uses another data set. It starts at ![]() and ends at
and ends at
![]() . During optimization of structural variables one keeps the best
fitting values of state variables
. During optimization of structural variables one keeps the best
fitting values of state variables ![]() and
and
![]() . These values are obtained by minimization of the sum
. These values are obtained by minimization of the sum
![]() . The data is from
. The data is from ![]() to
to ![]() . Here
the sum
. Here
the sum
,
Figures 15.4, 15.5, and
15.6 consider exchange rates of $/![]() and
DM/$.
and
DM/$.
Figures 15.7, 15.8, and
15.9 consider exchange rates of yen/$ and
franc/$.
Figures 15.10 reflect closing rates of AT&T (top) and Intel Co.(bottom) stocks.
Figures 15.13 , 15.14, and
15.15 consider the London stock exchange index.
Figures 15.16, 15.17, and
15.17 shows stock rates of the Hermis bank and
optimization results.
Figures 15.18 and
15.19 show the daily call rates of a call center
and illustrate optimization results.
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
To estimate unknown ARMA parameters we minimize a log-sum of
squared residuals defined by expression (15.60).
Estimates of parameters ![]() are from expression (15.13).
In most of the cases, figures show the multi-modality of log-sum (15.60),
as a function of parameters
are from expression (15.13).
In most of the cases, figures show the multi-modality of log-sum (15.60),
as a function of parameters ![]() .
Areas in vicinity of the global minima, often appear flat. A reason is that differences between values of the deviation
function
.
Areas in vicinity of the global minima, often appear flat. A reason is that differences between values of the deviation
function ![]() in an area around the global minimum are smaller as
compared with these outside this area (see Figures
15.15).
in an area around the global minimum are smaller as
compared with these outside this area (see Figures
15.15).
The maximal number of
Auto Regressive (AR) parameters ![]() was
was ![]() . Here
. Here ![]() , if no
external factors are involved. The optimal number
, if no
external factors are involved. The optimal number ![]() is defined
by structural stabilization (see Chapter 11).
Only two Moving Average (MA)
parameters
is defined
by structural stabilization (see Chapter 11).
Only two Moving Average (MA)
parameters ![]() were considered while plotting surfaces and contours. The results of Table 15.1
were obtained by optimization of both structural variables
were considered while plotting surfaces and contours. The results of Table 15.1
were obtained by optimization of both structural variables ![]() and
and ![]() .
.
The objective of this part of research is to show a
multi-modality arising in the prediction problem. Therefore, to save the computing
time, the global optimization is carried out approximately, using
not many iterations. The results of global optimization are
starting points for local optimization. The reason is
that the squared deviation as a function of parameters ![]() becomes uni-modal near the global minimum (see Figures
15.15). Therefore, the results are at least as
good as those obtained by the traditional local optimization.
becomes uni-modal near the global minimum (see Figures
15.15). Therefore, the results are at least as
good as those obtained by the traditional local optimization.
The high-accuracy
global optimization is very expensive. In the global
optimization, the computing
time is an exponential function of accuracy ![]() , in the sense that
, in the sense that
![]() .
Therefore, the problem of future investigations
is how to balance computing expenses and accuracy of estimates. This task is important
in both the time series prediction and the global optimization.
.
Therefore, the problem of future investigations
is how to balance computing expenses and accuracy of estimates. This task is important
in both the time series prediction and the global optimization.
The investigation of multi-modality of
squared deviation and variability of the parameters is the natural first step. The multi- modality is involved in
non-linear regression models, including the ARFIMA
ones.
We consider a version of an extended ARMA model that includes external factors (see expressions 15.28 and 15.29). The programs are in the files 'main.C', 'fi.C', and 'fitimeb.h' on the web-site (see Section 4). The first version of ARMA software is designed for data sets with no future data. That means that no future factors are not known. Therefore, the external factors are treated as missing data. It is assumed that future values of external factors are equal to the last ones. In the ARMA software under development, this is considered as the default case. In the new software version, the known future values of external factors will replace the default ones.
The results of a simple test are in the files 'test.out' and 'test.progn.out'. The data is in the file 'test.data', the initiation file is 'test.ini'. The results of the call rate example are in the files 'call.out' and 'call.progn.out'. The data is in the file 'call.data'. The initiation file is 'call2.ini'. The names of the data files are referred as INP in the initiation file INIFILE. The software is compiled and run this way:
Compile by 'make onestep', Run by 'onestep > results.out'
#define RAND() drand48(),defines the random number generator
#define S 0 /* number of rows of matrix c */ #define S 0 /* number of rows of matrix c */defines the bilinear component (see expression 15.50)
#define K 5 /*number of "multi-step" repetitions*/,K 5 means that the multi-step predictions is repeated 5 times (see Section 10 and Figure 15.23)
#define W 0 /*W 0 means the one-step structural optimization, W 1 defines the multi-step one*/,one-step structural optimization minimizes the average error of the "next day" predictions (see Section 11.3), multi-step one minimizes the average error of predictions for longer periods of time
#define V 1 /*V 1 means with the multi-step prognoses, V 0 means without*/the zero value of the indicator V switches off the multi-step prediction (see Section 10) and switches on the next day prediction (see Section 3.3 and Figure 15.23)
#define F 1 /*indicator of variance, F 1 involves variance*/,the unit value of the indicator F means that the variance of the errors
#define EPS 0/*indicator of residual printing*/,not used in this version
#define INP 0 /*indicator of input display*/,if INP 1 then the input values of the predicted factor are printed with their numbers (see Figure 15.24)
#define SA 0 /*indicator of simulated annealing */if SA 1 then optimization of the parameters p and q are performed using the simulated annealing method, otherwise the exhaustive search is used
#define PL 0/*plotting dimension*/,if PL 1 then the values of objective function depending on the parameter b[PLOT1] will be written in the file 'plot.out',
#define PLOT1 0 /*first plotting coordinate is b[PLOT1}*/ #define PLOT2 1/*second plotting coordinate is b[PLOT2}*/,defines which components of vector-parameter b are considered
#define A1 -1.5 /*lower bound of b[PLOT1}*/ #define B1 1.5/*upper bound of b[PLOT2}*/ #define A2 -1.5 /*lower bound of b[PLOT2}*/ #define B2 1.5/*upper bound of b[PLOT2}*/ #define DN 50 /*number of plotting steps*/defines the range and the density of the plotting points
#define ST 10000. /*temperature of simulated annealing */ #define SI 100 /*number of simulated annealing iterations*/defines the parameters of simulated annealing method (if SA is applied)
#define Ps M /*starting number of AR parameters*/ #define Qs 0 /*starting number of MA parameters*/ #define Pmin M /*minimal number of AR parameters*/ #define Qmin 0 /*minimal number of MA parameters*/ #define Pmax 2*M /*maximal number of AR parameters*/ #define Qmax 2 /*maximal number of MA parameters*/defines the initial, the minimal and the maximal number of parameters p and q in the structural optimization
#define T 120*M /* number of data entries in DATAFILE (divisible by M)*/,defines the total number of entries in DATAFILE
#define T0 T/3 /*T0<T number of entries for a and b optimization (divisible by M)*/ #define T1 2*T0 /*T1>=T0, number of entries for P and Q optimization(divisible by M)*/,divides the DATAFILE (see Figures 15.26 and 15.16) into three parts: the first part for a,b optimization, the second part for p,q optimization, and the third part for testing the results
 |
#define TR -1*M /*TR <= T, TR/M is the number of the first line in DATAFILE used for simple regression (negative TR prints no regression)*/ #define TE 25*M/*TE>TR, TE/M is the number of the last line for regression*/,is used only in the case when the ARMA model of time series prediction is reduced to the linear regression model of diagnosis.
#define INIFILE "bank2.ini",defines the input control file INIFILE (see Figure 15.27)
#define M 2 /*number of factors*/,defines the number of factors, including the predicted and the external ones
#define LOCAL_METH EXKOR,means that the EXKOR method is used for local optimization
#define GLOBAL_METH BAYES1means that the BAYES1 method is used for global optimization
#define BAYES1_MAX_IT 5*M /* bayes1 IT */ #define BAYES1_LT 5 /* bayes1 LT */means that 5*M iterations and 5 initial iterations of the BAYES1 method are used
#define EXKOR_MAX_IT 6*M /* exkor IT */ #define EXKOR_INIT_POINTS 6 /* exkor LT */means that 6*M iterations and 6 initial iterations of the EXKOR method are used
The test file is defined by 'test.ini':
INP test2 COL 1 COL 2Here INP defines the data file 'test2'
1. 1. 2. 1. 1. 1. 2. 1. 1. 1. 2. 1. 1. 1. 2. 1. 1. 1.Here COL 1 means that the first column of the file 'test2' should be considered as the factor to be predicted. COL 2 indicates the second column as an external factor.
A fragment of the optimization results is shown in the Figure 15.28.
 |
The applet 'index.html' is started by a browser, for example, by Netscape 4.6, or by the appropriate appletviewer. One clicks the button 'Show' (see the top Figure 15.30) to open the main window 'ARMA Frame' (see the bottom Figure 15.30). There are four buttons: 'File,' 'Input,' 'Options,' and 'Output' which open corresponding windows.
The option 'Local file' activates the 'Browse...'
button to select some local file.
The option 'Local URL' closes this button.
Then the contents of fields 'INI File' and 'Working directory or URL' determine the data file.
The file name, for example, 'arma.ini,' is in the field 'INI File.'
The file 'arma.ini' controls the data input from the test file 'arma.test.'
The directory is in the field 'Working directory or URL.'
If the 'Local URL' option is on, then the directory is, for example, this:
http:/optimum.mii.lt/~jonas/armajavajThe default URL is the applet directory.
acl.read=/home/jonas/public\_html/armajavaj/arma.ini acl.write=/home/jonas/public\_html/armajavaj/arma.outThat permits to read from 'arma.ini' and to write into 'arma.out.'
The file
![]() is the 'jar' archive including all the 'class' files.
is the 'jar' archive including all the 'class' files.
![]() or
or ![]() are archives of 'java' files.
are archives of 'java' files.
'index.html' is a starting applet.
'arma.ini' is the input control file.
'armatest' is the test data file.
The top Figure 15.30 shows the applet sign with the 'Show' button that starts ARMAJ. The bottom Figure 15.30 shows the initial window where the input file 'arma.ini' is defined. button that starts the ARMAJ.
 |
Figures 15.31 show the list of default values of control parameters, similar to those in the ARMA C++ version. The upper part of the list is on the top figure, the middle part is on the bottom one.
 |
The top Figure 15.32 shows the option window. The bottom Figure 15.32 shows the last fragment of the output window. Here the results, similar to those in the ARMA C++ version, are written.
The applet is started by a browser or by the appropriate appletviewer. First one clicks the label 'Model' (see the Figure 15.33) to select the data file, for example, the file 'armatest,
To select the parameters one clicks the label 'Inputs', see Figure 15.34).
The calculations are started by the label 'Count', Figure 15.35 shows the results.
The software is compiled and run this way:
Extract files by 'tar -zxf gmc.tgz' Rename the file 'fi.C.anngauss' by 'cp fi.C.anngauss fi.C' Compile by 'make', Run by './test'
It is easy to obtain daily stock rates for a long time. However, this information alone is not always useful while predicting the future stock rates [Mockus et al., 1997,Raudys and Mockus, 1999].
To improve predictions, one adds additional factors,
such as, relations of cash sales to the sum of inventories and credit sales.
However, these factors are available quarterly, as usual.
Therefore, it is difficult to unite them with the daily exchange
rates in the same model.
The aim of the Stock Rate Exchange Model is to explain
the poor predictability of stock rates.
Therefore, we start by considering the simplest case:
a single stock-broker, ![]() major customers
major customers ![]() ,
and
,
and ![]() joint-stock companies
joint-stock companies ![]() ..
..
One assumes that the stock rates ![]() of a joint stock company
of a joint stock company ![]() at a time
at a time ![]() depend on
bying-selling strategies of
customers
depend on
bying-selling strategies of
customers ![]() and some random factors
and some random factors ![]() .
At a time
.
At a time ![]() the customer
the customer ![]() orders a stock-broker to buy a number
orders a stock-broker to buy a number ![]() of
of ![]() shares , if
shares , if
The buying threshold is feasible if
.
In this case, the stock rate of the ![]() share at a moment
share at a moment ![]()
Here
The number of ![]() shares own by the customer
shares own by the customer ![]() at the time
at the time ![]() from (15.81)
assuming the feasibility condition (15.80)
from (15.81)
assuming the feasibility condition (15.80)
The profit of the customer ![]() during the interval
during the interval
![]()
Suppose, the customer ![]() predicts the stock rate of the
predicts the stock rate of the ![]() share for the time
share for the time ![]() using the Auto Regressive (AR) model:
using the Auto Regressive (AR) model:
The time series generated by Monte Carlo model depend on parameters ![]() that are not
defined by the model. To define these parameters, the "Nash Model" is used.
The Nash Model searches for such numbers
that are not
defined by the model. To define these parameters, the "Nash Model" is used.
The Nash Model searches for such numbers
![]() that satisfies the
Nash equilibrium conditions.
This means that no server can obtain higher expected profit
that satisfies the
Nash equilibrium conditions.
This means that no server can obtain higher expected profit ![]() by changing
by changing ![]() individually.
individually.
To ensure the existence of the Nash equilibrium one introduces
mixed strategies. Here the mixed strategy is to select the integer ![]() at random with probabilities
at random with probabilities
To make sense of this randomization, one repeates the Monte Carlo simulation ![]() times.
Denote
times.
Denote
![]() the
the ![]() -th sample of
the profit function
-th sample of
the profit function ![]() obtained by the
obtained by the ![]() -th player
using mixed strategies
-th player
using mixed strategies
![]() .
.
The average of all the ![]() samples:
samples:
Denote the "contract" vector by
![]() Define the "fraud" vector [Raudys and Mockus, 1999] as
Define the "fraud" vector [Raudys and Mockus, 1999] as
To compare the predictions of real and simulated stock rates
the well known ARMA model is used. The estimates of parameters ![]() of this model are obtained
by stabilization procedure.
of this model are obtained
by stabilization procedure.
This Java1.1 software implements the stock excange model in the case ![]() ,
, ![]() , and
, and ![]() .
That means two major players buying a single share at a time and one major joint stock company.
The purpose of this simplest case is to obtain some starting data and show advantages
and disadvantages of the model. This information helps developing more complicated mdels.
.
That means two major players buying a single share at a time and one major joint stock company.
The purpose of this simplest case is to obtain some starting data and show advantages
and disadvantages of the model. This information helps developing more complicated mdels.
Figure 15.36 describes the simulation
results in the case when
both players are predicting by the Wiener model:
![]() .
.
This conclusion is supported by the results of AR models
and partly
supported by the results of ARMA models [Mockus et al., 1997,Raudys and Mockus, 1999].
Using other models one may obtain different results.
For example, the AR model predicts better if the relation
![]() is
included as an external factor, where
is
included as an external factor, where
jonas mockus 2004-03-20















![\begin{figure}\begin{codebox}{4.7in}
\begin{verbatim}b[0] = -2.888616e-01
a[0...
...[10] = -1.432491e+03
a[11] = 8.030343e-01\end{verbatim}\end{codebox}\end{figure}](img1520.gif)







































![\begin{figure}\begin{codebox}{4.7in}
\begin{verbatim}progn t ymin[M*t] yav[M*t...
...89 1.647438e+02 2.618776e+02 3.345000e+02\end{verbatim}\end{codebox}\end{figure}](img1736.gif)



![\begin{figure}\begin{codebox}{4.7in}
\begin{verbatim}progn t ymin[M*t] yav[M*t...
...00000e+00 2.000000e+00
progn 0.000000e+00\end{verbatim}\end{codebox}\end{figure}](img1743.gif)














