Next: 18 SEQUENTIAL DECISIONS Up: 3 EXAMPLES OF MODELS Previous: 16 CALL CENTERS Contents Index
A failure to make a schedule or devising a wrong schedule can result in delay of a deadline and can cost much of the money [Ahuja et al., 1994,Hajdu, 1997].
First we consider a simple flow-shop scheduling problem. Here the sequence of tools is fixed by technology. One minimizes the make-span, which is the time from the beginning of the first task until the end of the last one. That is a well known simplest model presented just to illustrate how the Bayesian Heuristic Approach (BHA) [Mockus, 2000] could be applied in scheduling problems.
The second example is scheduling of traditional school that is closer to real life tasks. Here the sequence of teaching subjects, regarded as tools, can be changed. One needs to reduce the sum of gaps ("empty" hours) in the teacher schedules. There should be no gaps for students. Different classes are considered as different tasks. The classrooms, including the computer and physics rooms and studies, are the limited resources.
The most difficult example is scheduling of profiled school. Here eleventh and twelfth grade students are choosing , for example, 14 subjects from 64. This means that each student works by his own schedule. We search for the most convenient feasible schedule. The inconveniences are evaluated by penalty points.
All the software is available at the web-site
![]() and can be run by a standard browser with Java support.
and can be run by a standard browser with Java support.
Suppose that the sequence of machines ![]() is fixed for each job
is fixed for each job
![]() . One machine can do only one job at a time. Several machines
cannot do the same job at the same moment.
. One machine can do only one job at a time. Several machines
cannot do the same job at the same moment.
The objective function ![]() is the make-span
is the make-span ![]() , the time to
complete all the jobs.
, the time to
complete all the jobs.
In the example,
![]() , where
, where
![]() are numbers of
jobs, machines, and operations, respectively. Lengths and
sequences of operations are generated as random numbers uniformly
distributed from zero to ninety-nine. The expectations and
standard deviations are estimated by repeating forty times the
optimization of a randomly generated problem.
are numbers of
jobs, machines, and operations, respectively. Lengths and
sequences of operations are generated as random numbers uniformly
distributed from zero to ninety-nine. The expectations and
standard deviations are estimated by repeating forty times the
optimization of a randomly generated problem.
| |
|||||
| Algorithm | |||||
| BHA | 6.183 | 0.133 | 0.283 | 0.451 | 0.266 CPLEX |
"CPLEX" denotes the the well known general discrete optimization software after twenty hundred iterations (one CPLEX iteration is comparable to a Bayesian observation). Weak results of CPLEX show that the standard MILP technique is not efficient in solving this specific problem of discrete optimization. It is not yet clear how much one improves the results using specifically tailored B&B.
To optimize BHA parameters for a given Flow-Shop problem, one applies the Java optimization system GMJ2 that reduce the average deviation [Greicius and Luksys, 1999].
The optimal proportions of three heuristics: the Monte Carlo, the linear randomization and the "Select-the-Best" are on the output page (see Figure 17.1). The convergence line is there, too. These are results of one hundred iterations by the 'Bayes' method.
![[*]](footnote.png) , the second symbol ,
with the open one,
, the second symbol ,
with the open one,
The algorithm described in the previous section is for scheduling of traditional schools. In these schools the study schedules are fixed for each grade.
Application of this algorithm is more difficult, if classes are divided depending on subjects of choice. For example, some students may choose religion, some others ethics, e.t.c. Here the number of "classes" is greater because the schedules of divided classes of the same grade are different. In addition, classes are divided for some subjects and united for others, as usual.
In so-called "Profiled Schools" the students of eleventh and twelfth year select, for example, fourteen subjects from sixty available. That means different individual schedules for most of the students. There are no stable student classes anymore. They are replaced by changing "interest groups". The changes happen each hour.
Personal choices of eleventh and twelfth grade students are defined as sets of subjects. Sequences of these subjects and the corresponding class-rooms are defined by the general school schedule.
In this case a new approach is needed for optimal
scheduling.
An example is the commercial system ![]() .
The
.
The ![]() helps to produce feasible schedules by
performing corrections,
for example, by closing some gaps,
and informing about violated constraints and
inconveniences.
About 50% of the schedules produced by
helps to produce feasible schedules by
performing corrections,
for example, by closing some gaps,
and informing about violated constraints and
inconveniences.
About 50% of the schedules produced by
![]() depends on the human scheduler operating
depends on the human scheduler operating ![]() system.
Therefore, comparison with other systems is very difficult.
In this sense, the
system.
Therefore, comparison with other systems is very difficult.
In this sense, the ![]() and other similar systems
can be regarded mainly as "Support Systems."
and other similar systems
can be regarded mainly as "Support Systems."
The objective of this research is to design workable
optimization system for profiled school scheduling.
In the genuine optimization system a human operator
specifies just general objectives and constraints.
The schedules, both general and personal, are produced
automatically by an
optimization system. These schedules may be corrected by
an operator considering some additional factors not included
in
the general objectives and constraints.
The human operator can influence the outcome of optimization
by choosing an initial schedules, too
.
,
The general schedule is represented as an three-dimensional binary array
Personal schedules are defined for each interest group ![]() as three-dimensional binary arrays
as three-dimensional binary arrays
There are no schedules that satisfy all restrictions and personal preferences because they contradict each other as usual. For example, the ministry of education defines a number of rules to be observed, the school teachers and students both prefer schedules without gaps, etc. Thus, the objective is to find the best compromise of conflicting interests.
A compromise solution is reached by defining penalties
for violation of constraints and disregarding
inconveniences.
We search for such schedule that
minimizes the total penalty function. Only the "physical"
constraint may not be violated:
a person cannot be in two places at the same time.
We assume, that all other constraints may be violated, at a
price.
Both normative and convenience constraints are considered
in this research.
The standard restrictions are
is
,
are needed,
The usual factors of inconvenience are
Formally, the normative constraints cannot be violated.
Practically, some minor violations could be tolerated, if
this improves other parameters considerably. Thus
the normative penalties ![]() must be high.
must be high.
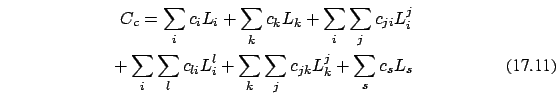
for the teacher ![]() ,
,
![]() is the number of days
is the number of days ![]() that are inconvenient
for the teacher
that are inconvenient
for the teacher ![]() ,
,
![]() is the number of hours that are inconvenient for
is the number of hours that are inconvenient for
the group ![]() ,
,
![]() is the number of inconvenient sequences of lessons.
is the number of inconvenient sequences of lessons.
The objective function is the total penalty
Using the Greedy Heuristics techniques one builds the schedule from scratch. Here the results depend on the sequence of "building" operations. This way, one obtains a schedule that is convenient for the
first teacher but may be very inconvenient for the last teacher, e.t.c.
As usual, greedy heuristics define priorities. That means that subjects, classes and persons that are higher on the priority list obtain better schedules. The schedule build by pure greedy heuristics often does not satisfy some important restrictions. Therefore randomization is introduced. It helps to build better initial schedule by random mixing of schedule lines and so extending the range of search.
A natural first step while trying to provide convergence
is the Simulated Annealing (SA):
One moves from the current schedule ![]() to the permuted schedule
to the permuted schedule ![]() with probability
with probability
The difference from the
traditional SA is that we optimize
the parameter ![]() for some fixed number of iterations
for some fixed number of iterations ![]() .
In this case the cooling schedule should be optimized, too.
A natural way to do it is by introducing the second
parameter
.
In this case the cooling schedule should be optimized, too.
A natural way to do it is by introducing the second
parameter ![]() .
This
transforms expression (17.14)
.
This
transforms expression (17.14)
SA and other discrete optimization techniques are explained in [Mockus, 2000] by the Knapsack example .
The profiled school scheduling software implements permutations similar to these of the traditional school considered in [Mockus, 2000]. That is only similarity. Important new ideas are developed and implemented while considering profiled school scheduling.
The fist one is that the schedule should be evaluated including both objective and subjective factors in a balanced way. The theoretical framework of this is the Pareto optimum. Simlest way to obtain Pareto optimal schedule is by assigning some penalty points for deviations from the desirable or feasible conditions. The total penalty is minimized. In such a case the penalty points represent subjective opinion of people responsible for schedules. The conditions reflects objective legal and physical factors.
The second new idea is optimization of heuristics by selecting their best parameters. That is achieved in three stages. In the first stage the same trivial permutation heuristics is used as in the traditional schedule. That works if one starts from nearly optimal schedule what is true in traditional schools as usual. In the profiled schools some "globalization" of permutation heuristics is needed.
That is achieved in the second stage by Simulated Annealing (SA) schedules applied with same fixed parameters such as initial "temperature" and the "cooling" rate The third fixed parameter is the probability to "miss" some teacher waiting in the "improvement" queue. In this case one accepts with some small probability schedules with higher penalties so improving convergence. It is easy to notice that the results of SA depend on all of three arbitrarily fixed parameters.
In the third stage these parameters are optimized using methods of stochastic global optimization developed in the framework of the Bayesian Heuristic Approach (BHA) [Mockus, 2000]. Each stage can be involved separately, that makes comparisons of their results much simpler.
There are two software versions: applet and servlet. The graphics of the applet version look better as usual, because graphical programs run at the user site. The servlet version runs using server resources. That is an advantage if user computing resources are limited.
This version implements only the first stage where the total penalty function is minimized locally using the simplest permutation heuristics That improves the initial schedules as usual. The advanced SA and BHA methods are implemented in the servlet version because servlet mode is more convenient providing schools with servers computing resources and better facilities for data exchange.
To run the applet
one visits the web-site
![]() ,
enters the problem named "School-PROFILED"
in the section "Discrete Optimization" and starts
,
enters the problem named "School-PROFILED"
in the section "Discrete Optimization" and starts
![]() by
a browser that supports Java.
by
a browser that supports Java.
Structure of the record is as follows:
1. Number of grade.
2. Subject code.
3. Teacher code.
4. Number of classrooms.
5. Number of classes per week.
6. List of attending students.
Records are not longer then 11 symbols. Fields are separated by the symbol |. The end of the line is marked by the symbol |^ For example, 11AngLg | ZenMar | 30 | 3 | 11LeonUla | 11KuprMin |^ 12MatLg | BirCer | 21 | 4 | 12GerdAbis | 12GirdSaru | 12GedLag |^Here the number
There are three servlet versions. The simplest one is direct implementation of the applet version. The updated version adds optimization of heuristics by Simulated Annealing (SA) with fixed parameters. The advanced servlet version optimizes parameters of SA completing software implementation of the main theoretical ideas of the Bayesian Heuristic Approach (BHA) (see Figure 17.8).
Figure 17.9 shows how data is uploaded, preferences and restrictions defined. In the upper-left corner is a list of topics. Marking some of them introduces "double time" preferences. Important restriction is maximal number of hours per day. The default valueIn the upper-right corner penalty points are defined. That is the subjective part of scheduling defined by persons responsible for scheduling reflecting informal local conditions and preferences.
The upper window in Figure 17.10
is for defining optimization parameters. Here the number of
iterations is ![]() , the initial probability to "miss" a teacher
is
, the initial probability to "miss" a teacher
is ![]() , both the initial "temperature"
, both the initial "temperature" ![]() and the
"cooling" rate
and the
"cooling" rate ![]() of SA are open.
of SA are open.
The middle window shows the difference between the initial
schedule (![]() penalty points) and the
optimized one (
penalty points) and the
optimized one (![]() penalty points).
To see the complete schedules one clicks on corresponding
words shown in the lower window of Figure 17.10.
penalty points).
To see the complete schedules one clicks on corresponding
words shown in the lower window of Figure 17.10.
The profiled school scheduling algorithms and software implements permutations similar to these of the traditional school considered in [Mockus, 2000]. That is only similarity. Important new ideas are developed and implemented considering profiled school scheduling.
The fist one is that the schedules should be evaluated including both objective and subjective factors in a balanced way. The theoretical framework of this is the Pareto optimum. Simlest way to obtain Pareto optimal schedule is by assigning some penalty points for deviations from the desirable or feasible conditions. The total penalty is minimized. In such a case the penalty points represent subjective opinion of people responsible for schedules. Desirable and feasible conditions reflects objective legal and physical factors.
The second new idea is optimization of heuristics by selecting their best parameters. That is achieved in three stages. In the first stage the same trivial permutation heuristics is used as in the traditional schedule. That works if one starts from nearly optimal schedule what is true in traditional schools as usual. In the profiled schools some "globalization" of permutation heuristics is needed.
That is achieved in the second stage by the Simulated Annealing (SA) schedules applied with same fixed parameters such as initial "temperature" and the "cooling" rate The third fixed parameter is the probability to delete the name of some teacher waiting in the "improvement" queue. In this case one accepts with some small probability schedules with higher penalties so improving convergence. It is easy to notice that the results of SA approach depend on all of three arbitrarily fixed parameters.
In the final stage these parameters are optimized using methods of stochastic global optimization developed in the framework of the Bayesian Heuristic Approach (BHA) [Mockus, 2000].
Each stage can be involved separately, that makes comparison of their results much simpler. Java implementation presents excellent opportunities to compare different scheduling versions for any interested person. The minimal user guide type information is presented in this paper to make easy the task of testing and applying the presented scheduling models.
The first few trials did show the better results as compared with the commercial software "MIMOSA" that now is used while scheduling Lithuanian profiled schools. However the statistical analysis of different school scheduling methods, algorithms and software systems is a separate important problem to be considered in future.
jonas mockus 2004-03-20













