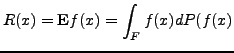Bayesian Heuristic Approach
Abstract
Results of complexity theory show the limitations of exact analysis. That explains popularity of heuristic algorithms. It is well known that efficiency of heuristics depends on the parameters. Thus we need some automatic procedures for tuning the heuristics. That helps comparing results of different heuristics. This enhance their efficiency, too.
In this paper the theory and applications of Bayesian Heuristic Approach are discussed. Examples of the Bayesian approach to automated tuning of heuristics are investigated.
All the algorithms are implemented as platform independent Java applets or servlets. Readers can easily verify and apply the results for studies and for real life optimization models.
The information is on the main web-site:
![]()
and four mirrors.
Optimization, Bayesian, Tuning Heuristics, Distance Studies
The efficiency of metaheuristics depends on parameters. Often this relation is defined by statistical simulation and have many local minima. Therefore methods of stochastic global optimization are needed to optimize the parameters.
The traditional numerical analysis considers optimization algorithms that guarantee some accuracy for all functions to be optimized. This includes the exact algorithms. Limiting the maximal error requires a computational effort that often increases exponentially with the size of the problem [1].
An alternative is the average analysis where the expected error is made as small as possible [2]. The average is taken over a set of functions to be optimized. The average analysis is called the Bayesian Approach (BA) [3,4]. Application of BA to optimization of heuristics is called the Bayesian Heuristic Approach (BHA) [5].
In the examples of this paper distances from the global minimum are not known. Thus the efficiency of methods is tested by comparing with average results of the "pure" Monte Carlo. Monte Carlo converges and does not depend on parameters that can be adjusted to a given problem by using some expert knowledge or additional test runs.
Possibilities of application are illustrated by several examples. designed for distance graduate studies in the Internet environment. All the algorithms are implemented as platform independent Java applets or servlets therefore readers can easily verify and apply the results for studies and for real life heuristic optimization problems.
Tuning of heuristics is regarded as an optimization problem.
We are looking for such parameters ![]() of heuristics
of heuristics ![]() that provide best results.
Denote the original function to be optimized as
that provide best results.
Denote the original function to be optimized as
![]() .
We know just that this function belongs to some family
.
We know just that this function belongs to some family ![]() of functions.
Thus we cannot define the optimization quality
by just a single sample
of functions.
Thus we cannot define the optimization quality
by just a single sample
![]() . All the
family
. All the
family ![]() have to be regarded.
Assume that search time is limited and defined as the number
have to be regarded.
Assume that search time is limited and defined as the number ![]() of iterations.
of iterations.
Denote by (
![]() ) the results obtained applying
) the results obtained applying ![]() times a heuristic
times a heuristic ![]() to a function
to a function
![]() . Here
. Here
![]() and
and
![]() , where
, where ![]() is the final decision
of heuristics
is the final decision
of heuristics ![]() after
after ![]() iterations.
Formally heuristic
iterations.
Formally heuristic ![]() after
after ![]() iteration transforms the original function
iteration transforms the original function
![]() into another
function
into another
function ![]() . Here
. Here
![]() belongs to a family
belongs to a family ![]() of functions
of functions ![]() transformed by heuristics
transformed by heuristics ![]() .
Transformed function
.
Transformed function ![]() shows how the value of the original function
shows how the value of the original function ![]() obtained applying
obtained applying ![]() times the heuristic
times the heuristic ![]() depends on
the heuristic parameters
depends on
the heuristic parameters ![]() .
.
Denote results of ![]() -th iteration as
-th iteration as ![]() .
Here
.
Here ![]() and
and
![]() .
Using the same heuristics parameter
.
Using the same heuristics parameter ![]() we obtain different results
we obtain different results ![]() depending on which sample function
depending on which sample function ![]() optimize. Thus here is optimization under uncertainty. In the optimization under uncertainty two different approaches are widely used:
optimize. Thus here is optimization under uncertainty. In the optimization under uncertainty two different approaches are widely used:
the Min-Max and the Bayesian.
The Min-Max approach minimizes the maximal deviation from the solution. Here
the worst case is regarded.
The Bayesian approach searches for minimal expected deviation.
Thus the average case is investigated.
If the family ![]() is a small set of well defined functions
is a small set of well defined functions ![]() then the Min-Max
approach is efficient.
Otherwise we regard the average case because the worst case is too bad.
then the Min-Max
approach is efficient.
Otherwise we regard the average case because the worst case is too bad.
Applying the Bayesian approach
we fix a prior distribution ![]() on a set
on a set ![]() of functions
of functions ![]() .
We need that defining average results.
A prior distribution is transformed into a posterior
distribution
.
We need that defining average results.
A prior distribution is transformed into a posterior
distribution ![]() on a subset
on a subset ![]() of the family of
of the family of ![]() .
We can do that by conditional probabilities.
.
We can do that by conditional probabilities.
Now we can define a risk function ![]() . The risk function
. The risk function ![]() shows
how the expected deviation
shows
how the expected deviation ![]() from the solution depends on parameters
from the solution depends on parameters ![]() .
Here
.
Here
![]() , where
, where ![]() is the optimal and
is the optimal and ![]() is a current
values of heuristic parameters. Owing to linearity of deviation
is a current
values of heuristic parameters. Owing to linearity of deviation ![]() the risk function
the risk function ![]() can be expressed as the difference
can be expressed as the difference
![]() .
The second component is a constant associated with the set
.
The second component is a constant associated with the set ![]() and
a prior distribution
and
a prior distribution ![]() . We see that
. We see that
![]() does not depend on the decisions
does not depend on the decisions ![]() therefore we disregard this component. Then we
can define the risk function as the expected value of
therefore we disregard this component. Then we
can define the risk function as the expected value of ![]()
In optimization problems theory and software are interconnected. The final results depend on the mathematical theory of optimization and the software implementation. Thus we have to regard them both.
That is just an initial part of the GMJ. Important is to make GMJ open for development by users. Users contribute their own optimization methods in addition to the Bayesian ones. User optimization models are included as GMJ tasks. The results of optimization are represented by GMJ analysis objects. A minimal set of methods, tasks, and analysis objects is implemented by default. The rest depends on users.
Monte Carlo is apparently the simplest method providing
convergence with probability one for any continuous objective function.
Thus we can test efficiency of global optimization methods by comparing
them with Monte Carlo search (3).
The analysis tool of GMJ "Convergence" defines how the best values of objective
functions depend on iteration number.
A method of search can be classified as
efficient only if it converges faster than Monte Carlo.
Other optimization methods change many variables at each iteration.
Here the 'Projection' shows how the density of observations depends on variables ![]() .
In efficient methods the density is higher around the global minimum.
.
In efficient methods the density is higher around the global minimum.
Comparing "Projection"
of different methods we see higher densities around global minima
in both Bayesian methods "Exkor" and "Bayes".
The illustration are projections of the Exkor and Bayes methods in Fig. 1. and Fig. 2.

|
|
The main objective of BHA is improving any given heuristic by defining the best parameters and the best ``mixtures'' of different heuristics. The examples indicate that heuristic decision rules mixed and adapted by BHA often outperform the best individual heuristics. In addition, BHA provides almost sure convergence. However, the final results of BHA depend on the quality of the specific heuristics including the expert knowledge. Therefore the BHA should be regarded as a tool for enhancing the heuristics but not for replacing them.
Many well known optimization algorithms, such as Genetic Algorithms [14], GRASP [15], and Tabu Search [16], may be regarded as metaheuristics that can be improved using BHA.
Genetic Algorithms [14] is an important "source" of useful stochastic search heuristics. It is well known that the results of the genetic algorithms depend on the mutation and cross-over parameters. The Bayesian Heuristic Approach could be used in optimizing those parameters.
In tabu search the issues of identifying best combinations of short and long term memory and best balances of intensification and diversification strategies can be obtained using BHA.
Hence, the Bayesian Heuristics
Approach can be applied to improve various stochastic or heuristic algorithms
of discrete optimization. The proved convergence of a discrete search method is an asset.
If not, then the convergence conditions are provided by tuning the BHA parameters
[17].
We remove the heuristic algorithm out of such non-optimal decisions
by taking decision ![]() with probability
with probability
![]() where
where ![]() is an increasing function of
is an increasing function of ![]() and
and
![]() is a parameter vector.
The BA is to optimize the parameters
is a parameter vector.
The BA is to optimize the parameters ![]() by minimizing the
best result
by minimizing the
best result ![]() obtained applying
obtained applying ![]() times the randomized heuristic algorithm
times the randomized heuristic algorithm ![]() .
.
Optimization of ![]() adapts the heuristic algorithm
adapts the heuristic algorithm ![]() to a given problem. Let us illustrate the parametrization of
to a given problem. Let us illustrate the parametrization of ![]() by three randomization functions:
by three randomization functions:
![]() Here the upper index
Here the upper index ![]() denotes the Monte Carlo component (randomization by the uniform distribution). The index
denotes the Monte Carlo component (randomization by the uniform distribution). The index ![]() defines the linear component of randomization. The index
defines the linear component of randomization. The index ![]() denotes
the pure heuristics with no randomization:
denotes
the pure heuristics with no randomization:
![]() if
if
![]() , and
, and
![]() , otherwise.
Here parameters
, otherwise.
Here parameters
![]() define the probabilities of using randomization
define the probabilities of using randomization ![]() .
The optimal
.
The optimal ![]() may be applied solving different but related problems, too [17]. That is important in the "on-line" optimization.
may be applied solving different but related problems, too [17]. That is important in the "on-line" optimization.
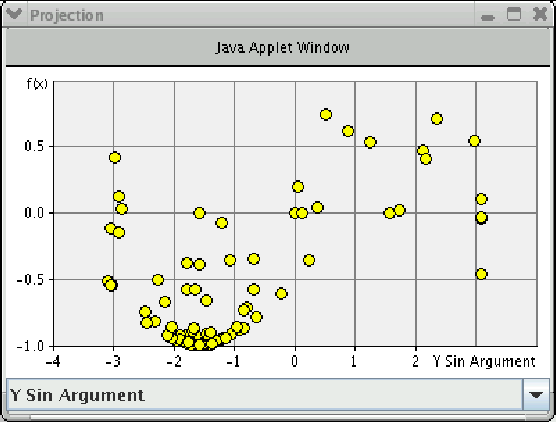
The first heuristic is denoted as "Random". Here we select cut elements with equal probabilities. The second heuristic is 'Max Size First'. The third heuristic is 'Min Size First'. The names speaks for themselves. We search for the best mixture of these three heuristics at fixed optimization time. The time parameter is important because the optimal mixture depends on the number of iterations.
A sample of optimization of a two-dimensional "guillotine" cut problem are in Fig. 3. Numbers
show how many times the corresopnding heuristic is used.
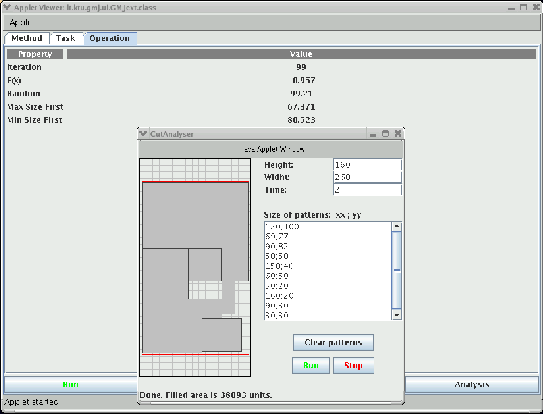
A sample of optimization of a three-dimensional packing problems is
in Fig. 4.
|
|
Permutations are made by trying to close the gaps between lectures. The best obtained schedule is recorded after each iteration. Changes to worse schedules are made with some probabilities. That is for improving convergence conditions.
Three different heuristics are regarded. Two heuristics with fixed parameters and the third heuristic with parameters obtained by global stochastic optimization.
Using the first heuristic
we keep the current schedule until the better schedule is found.
The parameter ![]() is the probability to pass by the next teacher.
This way we can reach just a sort of local minimum.
is the probability to pass by the next teacher.
This way we can reach just a sort of local minimum.
A natural first step to provide convergence
to the global minimum
is the Simulated Annealing (SA):
we move from the current schedule ![]() to the permuted schedule
to the permuted schedule ![]() with probability
with probability
The difference from the
traditional SA is that here we want to improve the average results
for some fixed number of iterations ![]() .
Thus the cooling rate should be regarded, too.
A way to do it is by introducing the cooling rate
parameter
.
Thus the cooling rate should be regarded, too.
A way to do it is by introducing the cooling rate
parameter ![]() .
.
This
transforms expression (4)
 describes
the "cooling rate".
describes
the "cooling rate".
The third heuristic optimizes all three parameters
 for a fixed optimization time defined by
the number of "internal"
for a fixed optimization time defined by
the number of "internal"![[*]](footnote.gif) iterations
iterations ![]() .
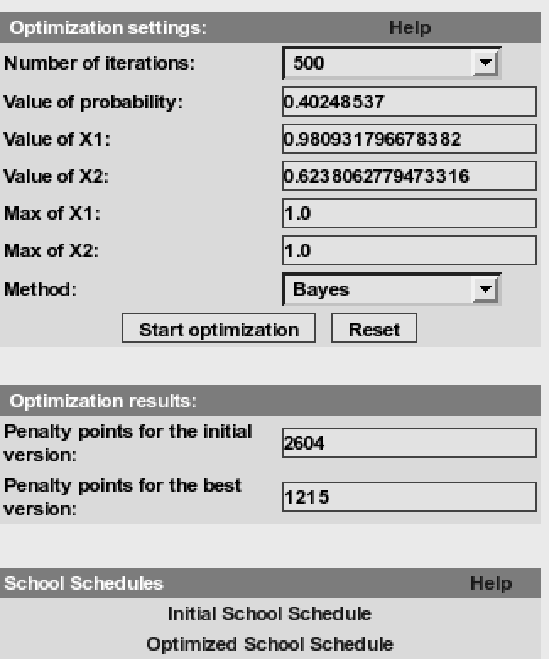
Fig. 5. shows the results of SA optimization in school scheduling.
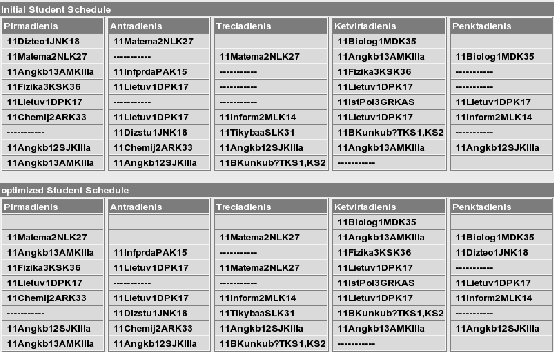
Fig. 6. shows initial and optimized student schedules.
.
Fig. 5. shows the results of SA optimization in school scheduling.
Fig. 6. shows initial and optimized student schedules.
|
|
|
|
The video-conferencing is regular:
each Friday from 8:00 until 9:30 EET (EEST).
Now the language is Lithuanian because no foreign students are connected.
However, the essential part of the web-site is in English so the English broadcasts
are possible, too.
The main difficulty for English speaking students apparently are early hours (7:00-8:30 CET) .
The connection is free. Static IP and NetMeeting is used. Advance notification is assumed. Interactive mode is easy using some standard
Audio and Video tools.
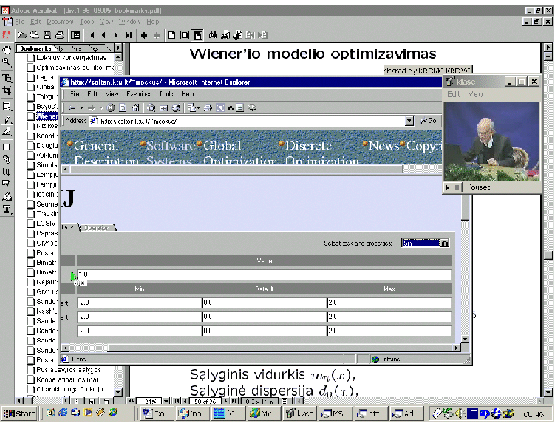
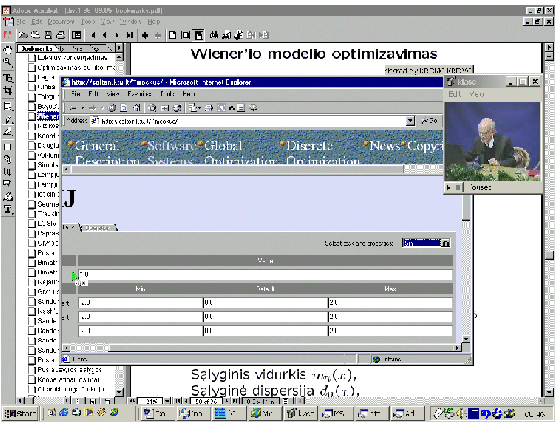
Fig. 7. is a snapshot of video-conferencing
about the Wiener model with
some "on-line" graphical explanations
in response to students questions.
|
This document was generated using the LaTeX2HTML translator Version 2002-2-1 (1.70)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -local_icons -split 3 -image_type gif -show_section_numbers -html_version 4.0 tune4.tex
The translation was initiated by mockus on 2006-05-01