Vytauto Didžiojo universitetas
Informatikos
fakultetas
Janina Prokopčikaitė
Prognozavimo ir diagnozavimo sistemos, naudojant laiko eilutes,
sudarymas, realizavimas interneto aplinkoje, bei tyrimas
Informatikos
magistro darbas
Verslo
informatika
Vadovas:
. prof. habil. dr. Jonas Mockus
Apginta:
…………………………….
(data, fakulteto dekano parašas)
KAUNAS
2003
Turinys
2. LAIKO EILUČIŲ MODELIŲ APŽVALGA, ARMA IR AR-ABS MODELIŲ TEORINIS TYRIMAS
2.1 Laiko eilučių auto regresiniai modeliai
2.2 Auto
regresinis slenkančio vidurkio
modelis
2.3 ARMA modelio
modifikacijos
2.4 Auto
regresinis mažiausių absoliutinių nukrypimų modelis
2.5 Tiesinis
programavimas absoliutinių didumų
metode
2.6 AR-ABS
ir ARMA modelių teorinis palyginimas
2.7 Auto
regresijos pritaikymas klasifikavimo uždaviniuose
3.1 Standartinių
elementų bei išorinių programų naudojimas
4. MODELIŲ EKSPERIMENTINIS TYRIMAS
4.2 AR-ABS modelio tyrimo metodika
4.4 Optimalus duomenų atsiminimo kiekis
4.5 Koeficientų
a įtaka prognozuojamai reikšmei
4.7 Išorinių faktorių įvertinimas
4.8 AR-
ABS, ARMA ir RW modelių palyginimas
4.9 Prognozavimas
eilę žingsnio į priekį
ARMA ir AR-ABS modeliais
4.10 Klasifikavimo
uždavinių sprendimas AR-ABS modeliu
SUTRUMPINIMŲ SĄRAŠAS
ARMA - Auto regresive moving average
AR-ABS - Auto regresive absolute values
ARFIMA - Auto regresive fractionaly integrated moving average
LP - linear programing
RW – Random Walk
TP - tiesinis programavimas
BL -
bilinear
ANN
-artificial neural network
ARIMA - AutoRegressive Integrated Moving-Average
ARFIMA - Auto Regresive Fractionaly Integrated Moving-Average
REFERATAS
Šiame
darbe realizuotas AR-ABS - mažiausių
absoliučių nukrypimų algoritmas. Tai laiko
eilučių klasei priklausančio auto regresijos modelio
modifikacija. AR-ABS modelis,
bei grafinė vartotojo sąsaja realizuota pasinaudojant Java
programavimo kalba. AR-ABS
algoritme pritaikomas tiesinis programavimas, naudojamas Michel Berkelar sudarytas tiesinio programavimo simplekso algoritmas.
Įvesta galimybė prognozuoti
įvertinat išorinių faktorių
įtaką, taip pat
prognozuoti eilę laiko
momentų į priekį.
AR-ABS modelio realizacija
be prognozavimo uždavinių
pritaikyta ir klasifikavimo – diagnozavimo uždavinių sprendimui.
Pasinaudojus
darbo metu sukurta
AR-ABS modelio realizacija
atliktas išsamus modelio
tyrimas: išanalizuota a
koeficientų įtaka prognozei,
išorinių faktorių įvertinimo
įtaka modelio daromai
paklaidai, optimalaus atimenamų į
praeitį laiko momentų
kiekiui ir t.t. Tyrimui
naudoti užsakymų priėmimo
telefonu centro „Call Center“ duomenys
(skambučių kiekis eilę dienų) ir
finansiniai AT&T kompanijos
akcijų kurso
kitimo duomenys.
Atliktas
teorinis auto regresinio slenkančio
vidurkio modelio ir
AR- ABS modelių palyginimas. Eksperimentiniam
modelių palyginimui ARMA
metodui duomenys buvo
surinkti pasinaudojant prof. J. Mockaus realizuotu ARMA modeliu.
Modelių daromų paklaidų
palyginimui be „Call
Center“ ir AT&T
kompanijos duomenų buvo
naudojami ir kiti
akcijų kurso bei
valiutų kurso kitimo duomenys.
Įvertinant
galimybę klasifikuoti AR- ABS
modelio pagalba buvo
naudoti skaitmenų ir
skyrybos simbolių atpažinimui
skirti duomenys.
AR- ABS modelis
žymiai geriau prognozuoja
finansinius duomenis, geriau
prognozuoja ir dideliais
svyravimais pasižyminčius nefinansinius duomenis, kas rodo
jog AR – ABS modelis ne taip jautriai kaip ARMA
reaguoja į stiprius
duomenų pokyčius.
Norint modelio pagalba spręsti didelius klasifikavimo uždavinius, simplekso algoritmą naudojamą, tiesinio programavimo uždaviniui spręsti, reiktų pakeisti kitu tiesinio programavimo metodu.
SUMMARY
In this work AR-ABS -the program for least absolute values of residuals model
was created. That's a modification of auto regressive moving average model that belongs to
the family of
time series models. AR-ABS
algorithm and graphical user
interface was created using
Java programming language.
In the AR-ABS model a linear
programming is applied, I
use Michel Berkelar
linear programming solver
constructed under simplex
algorithm. In program
there is a possibility to
predict involving external
factors, also possibility
to predict more
than one day
to the future. Program
is adjusted not
only to predict,
but also to solve
classification or diagnostic
problems.
After the program
was created, exhaustive inquiry
of AR-ABS model was done: analyzed influence of a multipliers
to prognosis, influence of external factors to average error of
the models, to optimal memorized
data quantity and
so on. The research was
done using Call
Center an AT&T company data.
There was
accomplished theoretical
and experimental comparison of
AR- ABS and ARMA
models, using Call
Center , AT&T company and other
financial data. Results of ARMA model were gathered using prof. J. Mockus realization of ARMA model.
Data intended to recognize numbers and punctuation
symbols was used
to investigate possibility
of using AR- ABS
model to solve classification problems and to compare
AR-ABS models results
with artificial neural
networks results.
After all,
I can say, that
AR- ABS model much
better predicts financial data (the
average residual of AR- ABS model prognosis is about 10
times less than ARMA) also
predicts better non
financial data with
strong fluctuation (the average
residual of AR- ABS model prognosis is 2 times less
than ARMA). So AR-ABS
model is less
sensitive than ARMA
to strong fluctuation
in data.
In order
to apply AR-ABS
model to bigger
classification - diagnostic
problems while using
Simplex algorithm to
resolve linear programming problem should
be used another linear
programming method instead.
1 ĮVADAS
Kone kiekviename
žingsnyje, mes bandome
bent kažkiek numatyti
į ateitį, spėti
ar prognozuoti kaip
keisis aplinka. Jei
senovėje dažniausiai buvo bandoma
nuspėti orus, tai
šiais laikais orai,
o tiksliau meteorologija yra tik viena
iš daugelio sričių,
kur naudojamas prognozavimas. Dar viena labai
svarbi sritis, kur
naudojamas prognozavimas - seismologija. Be gamtos reiškinių
prognozavimo šiais laikais
svarbi prognozavimo naudojimo
sritis - ekonomika. Akcijų
kurso, valiutų kurso
ir kitų finansinių rodiklių
prognozavimas reikalingas daugelio
investavimo klausimų sprendimui. Darbo tvarkaraščių sudaryme,
gamybos planavime prognozavimas taip pat vaidina
svarbų vaidmenį, kadangi
tikslus produkcijos poreikio
numatymas yra svarbus
optimalus gamybos plano sudarymo faktorius.
Šiais
laikais, mokslui pažengus toli į
priekį, prognozavimo bei diagnostikos
funkcijas atlieka kompiuteriai, o tiksliau
įvairiais matematiniais skaičiavimais pagrįsti algoritmai ir metodai
naudojantys per eilę metų
surinktus duomenis apie aplinką,
tuo iš esmės prognozavimas
ir skiriasi nuo spėjimo, kur
ateities numatymas remiasi
tik intuicija ir subjektyviais samprotavimais ar subjektyviais reiškinių susiejimais.
Siekiant
kuo didesnio prognozavimo
tikslumo kuriami nauji
metodai, modifikuojami jau
sukurtieji ar pritaikomi tiesioginės paskirties prognozavimui neturėję metodai pvz.:
ekspertinės sistemos. Ir atvirkščiai
prognozavimui naudoti metodai
pritaikomi klasifikavimo -
diagnozavimo uždaviniams spręsti
pvz.: medicinoje, nustatant
paciento priklausymą vienai
ar kitai rizikos
grupei.
Laiko eilučių
modeliai yra vieni tinkamiausių prognozavimo
uždaviniams spręsti. Vienas
seniausių yra auto regresinis slenkančio
vidurkio modelis ARMA. Iš šio
modelio išsirutuliojo visa
eilė daugiau ar mažiau ištirtų
modifikacijų.
AR-ABS - mažiausių absoliučių nukrypimų
modelis yra viena šio modelio, modifikacijų, tiksliau tai AR
modelis, kur vietoj
mažiausių kvadratų metodo
paklaidų minimizavimui naudojamas
paklaidų absoliutiniais didumais
minimizavimas. Todėl šiame darbe
bus skiriamas didelis
dėmesys AR-ABS ir
ARMA modelių teoriniam,
eksperimentiniam palyginimui,
taip pat ir AR-ABS modelio tinkamumo
klasifikavimo uždaviniams spręsti
nustatymui.
2
LAIKO EILUČIŲ
MODELIŲ APŽVALGA, ARMA IR AR-ABS MODELIŲ
TEORINIS TYRIMAS
2.1 Laiko eilučių auto regresiniai modeliai
Laiko eilučių
modelius yra įprasta
taikyti prognozavimo uždaviniuose. Ekonominių ir financinių
laiko eilutčių modeliavimas ARMA modelio pagalba pastaraisiais metais
patraukė daugelio mokslininkų dėmesį (Diebold and
Rude- Busch, 1989; Cheung,
1993; Yin-Wong and
Lai., 1993; Cheung
and Lai, 1993; Koop
et al., 1994;
Mockus and Soo_,
1995). Įvertinant ARMA
modelio parametrus buvo
naudojami trys požiūriai:
·
maksimalios
tikimybės (Sowel, 1992);
·
approksimuotos
maksimalios tikimybės (Li and
McLeod, 1986; Fox and Taqqu, 1986;
Hosking, 1981; Hosking, 1984),
dviejų žingsnių
procedūros two-step
procedures (Geweke and Porter-Hudak, 1983; Janacek, 1982).
[3;6]
Visais atvejais
buvo taikomi lokalaus optimizavimo metodai. Tokiu būdu
rezultatai priklauso nuo
pradinių įverčių, kas reiškia
jog galiniame etape
nebūtinai globalus maksimumas
ar minimumas bus
rastas.
Globali
optimizacija daugeliu atvejų
yra sudėtingas uždavinys.
To priežastis - labai
painūs, daugia-modaliai optimizavimo uždaviniai. Yra
gerai žinoma jog polinominės eilės
suskaičiuojamų relių funkcijų
optimizavimas negali būti
atliktas per polinominį laiką,
nebent P = NP. Praktiškai tai
reiškia, kad reikalingas eksponentinės eilės
algoritmas, norint gauti
sprendinį ε- tikslumu. Operacijų
kiekis eksponentiniuose algoritmuose auga eksponentiškai su
sprendinio tikslumu m
ir optimizavimo uždavinio dydžiu n. Tikslumas m
reiškia jog ε mažiau arba lygu 2laipsniu -m, o
dydis n reiškia
jog optimizuojama funkcija
f(x), kur x=(x1,…..,xn). [3;6]
Populiarus požiūris įvertinant
ARMA modelio parametrus
yra mažiausių kvadratų
metodas. Tuo tarpu
absoliutinių nukrypimų metodas
yra mažai žinomas.
Žinios apsiribojo idėja
mažiausius kvadratinius nuokrypius pakeisti nuokrypiais absoliutiniu didumu. Pagrindą
padėjo Charnes, Cooper ir
Ferguson dar 1955 metais
išleistame veikale apie matematinio
programavimo pritaikymą
statistikoje. Jie pirmieji pasiūlė
tiesinės regresijos modeliuose mažiausių absoliutinių nukrypimų
minimizavimą pakeisti nukrypimų
absoliutiniais didumais sumos
minimizavimu įvardindami šį
metodą - MINMAD [5]. Taip
pat jie išdėstė atitikimą
tarp MINMAD metodo ir tiesinio programavimo. Wagneris 1959 metais pasiūlė problemą
spręsti dualiuoju požiūriu. Barrodalo
ir Robertso (1973m.) efektyvus
simplekso algoritmo modifikavimas padidino galimybę
naudoti MINMAD regresiją kaip alternatyvą klasikinei regresijai [5]. Lygiagrečiai buvo plėtojamas matematinio programavimo ir statistikos panaudojimas ir kitose srityse. Ir vis tik galima teigti jog J. Mockus
vienas iš pirmųjų
pasiūlė būdą kaip
realizuoti mažiausių absoliutinių nukrypimų metodą ir
jo taikymą auto regresiniuose
laiko eilučių modeliuose, kadangi
jo idėjos ir tyrimai nesirėmė aukščiau pristatytų mokslininkų idėjomis
ir veikalais.
2.2 Auto regresinis slenkančio vidurkio modelis
Iš visos laiko eilučių
klasės algoritmų artimiausias (AR-ABS) modeliui
žinoma yra ARMA
modelis, nes būtent
šio modelio pagrindu
mažiausių kvadratų metodą
pakeitus absoliutinių dydžių
sumavimu ir sukurtas
AR- ABS modelis.
2.2.1 ARMA modelio išraiška
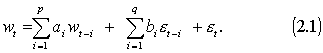
Formaliai ARMA modelį
galima aprašyti tokiomis
formulėmis:
![]()
Tarkim turime užsakymų priėmimo telefonu centro,
priimančio prekių užsakymus telefonu duomenis:
wt -
prognozuojamas skambučių kiekis rytdienai;
wt-1 - šios
dienos skambučių kiekis;
p -
dienų kiekis - kiek atsimenam
į praeitį;
-
![]() atsitiktinė paklaida
rytoj;
atsitiktinė paklaida
rytoj;
-
ai,
bi
įtakos koeficientai;
wt
ARMA
modelyje prognozuojamos reikšmės
gavimą galima būtų padalinti
į trijų dalių sumą: tam tikro kiekio p prieš tai buvusių reikšmių wt-i padaugintų iš
optimizavimo metu rastų
koeficientų ai sumos
vadinamos auto regresijos dalimi,
metodo duodamų et-i paklaidų
sandaugos su atitinkamais
koeficientais bi sumos
vadinamos slenkančio vidurkio
dalimi ir e t nežinomų
aplinkos veiksnių dar
vadinamų baltuoju triukšmu. Susidaro įspūdis jog gauti prognozę yra
visai paprasta, tereikia turėti duomenų seką t.y. laiko eilutę, tačiau čia
svarbu pabrėžti jog prognozės tikslumas labai priklausys nuo a ir b
koeficientų arba metodo,
kurio pagalba jie bus
rasti. Žinoma nereikia pamiršti jog svarbi ir pati laiko eilutė ar tai
prognozuojami duomenys, ar tiesiog
atsitiktinių skaičių seka, kuomet
joks metodas patenkinamai nesuprognozuos koks bus
sekantis atsitiktinai suprognozuotas skaičius.
![]()
2.2.2 Nuokrypių išraiškos ARMA modelyje
Paklaida arba kitaip nuokrypiai išreiškiami
sekančiomis lygybėmis :
![]()
![]()
…………………………………….
![]()
Duodamas modelio
nuokrypis kiekvienu laiko momentu -
tai skirtumas tarp w reikšmės tam tikru momentu ir
apskaičiuotos w’ reikšmės pagal praeities duomenis
iki to momento pagal formulę
(2.1) neatsižvelgiant į baltąjį
triukšmą.
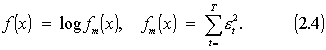
Tuomet yra
minimizuojama kvadratinių
nuokrypių suma:
Logaritmas naudojamas
siekiant sumažinti nuokrypius.
Toliau optimizavimo uždavinys
suvedamas į tiesinių
lygčių sistemos sprendimą.
2.2.3 Paklaidos minimizavimas ARMA modelyje
ARMA metodo paklaidos minimizavimo algoritmas yra gana
paprastas. Pažymėkime, kad yt yra
kažkokia y reikšmė laiko momentu t. Pažymėkime,
kad a = (a1,……,ap)
yra auto regresijos AR parametrų
vektorius, o b = (b1,……,bq)
- slenkančio vidurkio
parametrų MA vektorius:
 (2.5)
(2.5)
Tuomet nuokrypis arba paklaida bus:
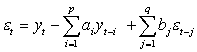 (2.6)
(2.6)
Pastarąją
lygybę galima užrašyti sekančiai:
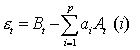 . (2.7)
. (2.7)
Kur B ir
A išraiškos apibrėžiamos tokiomis lygybėmis:
 , (2.8)
, (2.8)
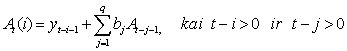 . (2.9)
. (2.9)
2.2.4 Auto regresijos AR parametrų optimizavimas
Pažymėjus:
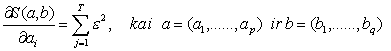 (2.10)
(2.10)
Iš (2.7) ir (2.10) išraiškų
kad minimumo sąlyga
yra:
 (2.11)
(2.11)
arba
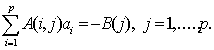 (2.12)
(2.12)
A(i,j)
ir B(j) galima išreikšti sekančiomis
lygybėmis:
![]() (2.13)
(2.13)
ir
![]() (2.14)
(2.14)
Esant fiksuotiems parametrams b, (2.10)
išraiškos minimumas apibrėžiamas
tiesinių lygčių sistema:
![]() (2.15)
(2.15)
A –1 - matrica
atvirkštinė matricai A =(A(i,j), i, j =1,….p), kurios A(i,j) elementai
apskaičiuojami pagal (2.13) išraišką,
B
=(B(j), j =1,….p), vektorius kurio komponentai B(j) apskaičiuojami
pagal (2.14) išraišką.
Tokiu
būdu apibrėžiamas parametras a(b) =(ai(b), i =1,….p), kuris esant fiksuotiems
parametrams b, minimizuoja (2.11)
formulėje pateiktą sumą.
2.2.5 Slenkančio vidurkio MA parametrų optimizavimas
Kvadratu pakeltų
paklaidų suma iš (2.11)
formulės yra netiesinė b parametrų funkcija. Tokiu
atveju reikia taikyti globalios optimizacijos algoritmus.
Pažymėkime, kad:
![]() (2.16)
(2.16)
Čia x = b ir S(a,b) yra iš (2.11)
formulės prie optimalaus parametro
a = a(b).
Pažymime, kad:
![]() (2.17)
(2.17)
2.2.6 Išorinių faktorių įvertinimas ARMA modelyje
Prognozuojamas dydis
priklausomai nuo jo
specifikos gali priklausyti
nuo eilės įvairių
faktorių, pvz. įvairūs pardavimo apimčių rodikliai gali priklausyti
nuo šventinių laikotarpių, vykstančių renginių, reklaminių
akcijų, varžybų ar
net oro temperatūros. Visi šie faktoriai gali būti
žinomi iš anksto ir
prognozuojant rytdienos skambučių kiekį
galime remtis ne tik praeityje
priimtų skambučių kiekiu, bet
ir žinomais išoriniais faktoriais.
Pažymėkime prognozuojamą objektą, šiuo atveju skambučių kiekį įtakojančių faktorių
reikšmes vektoriumi h(t) = (h1(t), h2(t), …,hM(t)), o
prognozuojamą reikšmę (skambučių kiekį) v(t). Kai
kurių išorinių faktorių
poveikis prognozuojamai reikšmei
gali būti su vėlinimu.
Modeliavimui atmesim
slenkančio vidurkio dalį
ir tarsime jog išorinių faktorių vektorius yra
dvimatis, tuomet prognozę
laiko momentui t galima išreikšti sekančia
lygybe:
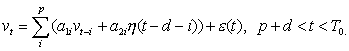 (2.18)
(2.18)
Kintamasis
d apibrėžia vėlinimą.
Prie fiksuoto parametro
d minimizuojama kvadratinių
nuokrypių suma, o
po to parenkamas optimalus vėlinimas
d. Kvadratinių nuokrypių
sumos minimumas (funkcija nuo a parametrų) yra
apibrėžiamas tiesinių lygčių
sistema:
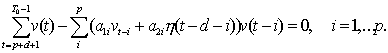 (2.19)
(2.19)
 (2.20)
(2.20)
Koeficientai
a yra randami iš dalinių
išvestinių prilygintų nuliui
lygčių sistemos. Tenka
spręsti 2p tiesinių lygčių su 2p
kintamųjų a1i, a2i, i =
1,..,p. Tokiu būdu gaunami a1i(d), a2i(d), ir 1,…,p
esant duotam d.
Kiekvieno išorinio
faktoriaus vėlinimas dažnai
nėra būtinas. ARMA
modelio išraiška kartu
su išoriniais faktoriai,
bet tik atmetus
d dalį išreiškiama
sekančia lygybe:
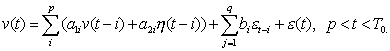 (2.21)
(2.21)
Kuomet turime daugiau nei du faktorių,
pvz.: M išorinių
faktorių (2.21) lygybę galima užrašyti bendresne forma, kur visi praeities duomenys yra traktuojami kaip išoriniai faktoriai:
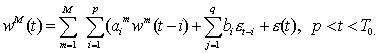 (2.22)
(2.22)
Tokia ARMA
modelio išraiška su
išorinių faktorių įvertinimu
gali būti pritaikyta,
ne tik prognozavimo, bet
ir diagnozavimo- klasifikavimo uždaviniams
spręsti. Plačiau išorinių
faktorių įvertinimo panaudojimas diagnozavime bus pateiktas
atskirame skyriuje.
2.3 ARMA modelio modifikacijos
AR-ABS tai tikrai ne pirmoji ARMA modelio modifikacija, plačiai žinomos ARIMA, ARFIMA modifikacijos.
Galima teigti jog ARMA modelį išpopuliarino Box ir Jenkins. Nors AR ir MA modeliai buvo žinomi ir naudojami gan senai Box ir Jenkins pateikė sistematinį požiūrį kaip apjungti AR ir MA modelius į vieną, taip pat suformulavo modifikaciją ARIMA [10].
ARMA, ANN, ir BL (bilinear) modeliai analizuoja
stacionarias laiko eilutes.
Modelio stacionarumas tai
realybės supaprastinimas. Gerai
žinomas nestacionarumo šaltinis
yra tiesinė komponentė
- trendas. Kadangi tiesinės
funkcijos išvestinė yra
konstanta, tad trendas
eliminuojamas diferencijuojant.
Šis metodas taikomas ARIMA
bei ARFIMA modeliuose.
ARIMA (AutoRegressive Integrated Moving-Average) - auto regresyvus integruoto
slenkančio vidurkio modelis,
kartais dar vadinamas Box-Jenkins modeliu. ARIMA modelis prognozuoja dydį pagal laiko eilutės tiesinę kombinaciją
su jos praeities dydžiais,
praeities paklaidomis ir dabarties
bei praeities kitų laiko eilučių įverčiais. Kuomet ARIMA modelis
apima kitas laiko
eilutes kaip įėjimo
duomenis, toks modelis
vadinamas ARIMAX. Tokį modelį
Pankratz (1991) apibūdina kaip dinaminės regresijos modelį [10].
ARFIMA (Auto Regresive
Fractionaly Integrated Moving-Average) modelis apima ARIMA
modelį, t.y. pastarasis modelis
yra atskiras ARFIMA
modelis kuomet d- yra
sveikas teigiamas skaičius (d- diferencialo eilės
numeris), kuomet d=0 turime
ARMA modelį. Dažnai
empirinis modeliavimas apima identifikavimą, įvertinimą
ir testavimą. ARIMA modeliavimo identifikaciniame
lygyje apibrėžiama sveikoji diferencialo eilės dalis
d, auto regresijos ir slenkančio
vidurkio eilės p
ir q. ARFIMA modelyje galima
įvertinti d parametrą ir
apskaičiuoti patikimumo intervalą
[9].
Nepaisant to,
jog ARIMA modelis gerai
pašalina trendą nestacionariuose laiko eilutėse taip
būna tik tuomet
kai parametrai nesikeičia
laike arba keičiasi
lėtai.
Bendrai paėmus
visiems ARMA modeliams ir jų
modifikacijoms kai kurie
autoriai rekomenduoja naudoti
bent 50 momentų laiko
eilutes [9].
2.4 Auto regresinis mažiausių absoliutinių nukrypimų modelis
Kadangi mažiausių kvadratų metodas yra labai
jautrus dideliems nukrypimams
duomenyse pvz.:
minimizuojant kvadratinius nuokrypius
didelis nuokrypis toks
kaip 100 turi tokią
pat įtaką kaip
ir dešimt tūkstančių mažų lygių vienetui nuokrypių. Todėl kilo
idėja mažiausių kvadratinių
nuokrypių minimizavimą pakeisti
nuokrypių absoliutiniais didumais
minimizavimu [3; 6].
2.4.1 AR-ABS modelio išraiška
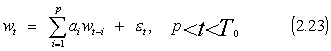
Pasinaudotojus (2.1),
(2.2) lygybėmis ir
eliminavus slenkančio vidurkio
dalį AR - ABS modelis
apibrėžiamas taip:
Parametrai apibrėžiami
analogiškai kaip ir ARMA
modelyje:
wt - prognozuojamas skambučių kiekis
rytdienai;
wt-1 - šios
dienos skambučių kiekis;
p -
dienų kiekis - kiek atsimenam
į praeitį;
-
![]() atsitiktinė paklaida
rytoj;
atsitiktinė paklaida
rytoj;
-
ai,
bi
įtakos koeficientai;
Prognozuojamas
dydis priklauso nuo prieš tai buvusių
reikšmių ir tam
tikro aplinkos poveikio,
kuris apibrėžiamas kaip atsitiktinė skaičių seka, pasiskirsčiusi pagal Gauso dėsnį.
Trumpai tariant tai
yra AR modelis
ir tik a koeficientų radimui
čia bus taikomas ne mažiausių kvadratų, o absoliutinių didumų metodas.
2.4.2 Nuokrypių išraiška AR-ABS modelyje
Pasinaudojus (2.23)
formule nuokrypius galima išreikšti sekančiomis lygybėmis:
![]()
![]()
………………………………
![]()
Paklaida et lygi prognozuojamos reikšmės
ir iki jos turimų
reikšmių sandaugos su
koeficientais a skirtumu. Ir be abejo minimizuodami paklaidą et , gausime
tokius koeficientus a,
su kuriais paklaida bus minimali.
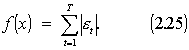
Sekantis žingsnis
yra
funkcijos minimizavimas. Šis absoliutinių
nuokrypių sumos minimizavimas atskleidžia AR-ABS
pavadinimo prasmę.
2.4.3 Paklaidos minimizavimas AR-ABS modelyje
Funkcijos f(x) minimizavimui taikomas tiesinis programavimas. Tiesinė tikslo funkcija
išreiškiama formule:

Tiesinės tikslo funkcijos
sprendinio leistinoji sritis
sudaroma iš sekančių ribojimų -
nelygybių:
![]()
![]()
![]()
AR-ABS modelyje įvedama dar viena
modifikacija, kiekvieną koeficientą
a sudaro dviejų komponenčių
vektoriai (2.29). Ši
modifikacija savo ruožtu
sumažina modelio jautrumą
dideliems nuokrypiams [3; 6.3].
Tiesinio
programavimo užduoties sprendimui
galima taikyti visą
eilę tiesinio programavimo algoritmų: simplekso, elipsoidų metodą, Karmarkar'o algoritmą
(vidinio taško metodas) kurių privalumai ir trūkumai bus aptarti atskirame
poskyryje.
2.4.4 Išorinių faktorių įvertinimas
Prognozuojamas dydis
priklausomai nuo jo
specifikos gali priklausyti
nuo eilės įvairių
faktorių, pvz. įvairūs pardavimo apimčių rodikliai gali priklausyti
nuo šventinių laikotarpių, vykstančių renginių, reklaminių
akcijų, varžybų ar
net oro temperatūros. Tarkime
prognozuojamą objektą, šiuo
atveju skambučių kiekį
įtakoja M faktorių, tuomet
AR-ABS modelį anksčiau apibrėžtą
(2.5) formule galima
modifikuoti, kiekvieną a koeficientą ir w reikšmę
sudarys M komponenčių vektorius:

Tai yra
bendresnis AR-ABS modelis, jį
galima taikyti ir
prognozavimui neįvertinant išorinių
faktorių priimant, kad
M=1. Siekiant supaprastint programinę tokios formulės
realizaciją ją galima
perrašyti taip:

Formulėse (2.30) ir (2.31) atitikmenys:
![]()
2.5 Tiesinis programavimas absoliutinių didumų metode
Algoritmo tiesinio programavimo uždaviniams
spręsti išradėjas ir šios
mokslo srities krikštatėvis G. Danzig teigia, kad
„Tiesinį programavimą galima
vertinti kaip revoliucinį
išradimą , įgalinantį žmoniją
praktinėse sudėtingose situacijose
nusibrėžti aiškius tikslus ir
detaliai pagrįsti geriausius
žingsnius tiems tikslams
pasiekti“ [1; 162 p.].
Moksliškai tiesinis
programavimas apibrėžiamas kaip
optimizavimo uždavinių su
tiesine tikslo funkcija
ir tiesinėmis lygybėmis
bei nelygybėmis apibrėžta
leistinąja sritimi sprendimas.
Bendruoju
atveju , tiesinio programavimo uždavinys matriciniais
žymėjimais gali būti
užrašytas taip:
minCX,
AX = B,
A’X ³ B’ (2.33)
x1 ³ 0,….,xr ³ 0,
Kur
kintamasis X yra n-matis vektorius,
A matrica su išmatavimais l x n, A’ matrica
su išmatavimais (m-l) x n, B ir B’ sudaro
m- matį vektorių. Vektoriaus
X pirmosios r komponenčių turi būti neneigiamos, o kitų X komponenčių
ženklas gali būti
bet koks. Aukščiau pateikta
tiesinio programavimo uždavinio bendroji forma, tačiau
atskirais atvejai gali
būti parankiau naudoti
standartinę arba kanoninę
uždavinio formas.
Standartinė TP uždavinio forma:
min CX,
AX = B, X ³ 0. (2.34)
Kanoninė TP
uždavinio forma:
min CX,
AX ³ B, X ³ 0. (2.35)
Visos trys
tiesinio programavimo formos
yra visiškai ekvivalentiškos ir bet kurį
TP uždavinį galima
užrašyti tiek bendrąja,
tiek standartine, tiek
kanonine formomis.
Tiesinio programavimo uždaviniai pasižymi tuo
jog tikslo funkcija
yra tolydi ir
esant apibrėžtai leistinajai sričiai minimumo taškas
visada egzistuoja. Jei
leistinoji sritis neapibrėžta , galima parinkti tokius
tikslo funkcijos koeficientus, kad tikslo funkcijos
reikšmės leistinoje srityje
neapibrėžtai mažėtų. Toks
atvejis vadinamas neapibrėžtu tiesinio programavimo uždaviniu.
Tiesinio
programavimo uždaviniams spręsti naudojama eilė algoritmų.
Vienas iš anksčiausiai pradėtų naudoti
ir geriausiai ištirtų yra Simplekso algoritmas.
Geometriškai tiesinio programavimo uždavinio sprendimas –
perėjimas iš vienos leistinosios srities
viršūnės į kitą
tikslo funkcijos mažėjimo
kryptimi. Perėjimas į kaimyninę
viršūnę gali būti
realizuotas atraminiu bazės
keitimu, bazė vienareikšmiškai apibrėžia
leistinąjį bazinį sprendinį.
Tikslo funkcijos reikšmės
mažėjimą užtikrinantis į bazę
įkeliamo stulpelio parinkimas
ir atraminis bazės
keitimas sudaro simplekso
algoritmo pagrindą. Tačiau
numatymas tik vieno
žingsnio į priekį
gali duoti ir
ne pačius geriausius rezultatus.
Perėjimas į kaimyninę viršūnę,
kurioje tikslo funkcijos
reikšmė minimali, gali
būti nelabai racionalu todėl,
kad naujoji viršūnė
gali būti neperspektyvi tolimesnės paieškos požiūriu,
tačiau įvertinti kelių
algoritmo žingsnių rezultatą
labai sudėtinga, žymiai paprasčiau
nustatyti, ar tikslo funkcijos
reikšmė sumažės, negu
įvertinti, kokio dydžio bus
sumažėjimas. Taip pat
svarbu pažymėti jog
tam, kad rasti
optimalų sprendinį optimizaciją būtina pradėti nuo
kokio nors leistinojo
bazinio sprendinio. Tarkime,
leistinasis bazinis sprendinys
žinomas, kadangi jį
galima rasti išsprendus
kitą panašų uždavinį.
Kadangi simplekso algoritmas
kaip potencialius sprendinius
tikrina poliedro viršūnes,
tai tikrinimų skaičius
yra baigtinis, blogiausiu atveju
sutampantis su poliedro
viršūnių skaičiumi. Jei tiesinio
programavimo uždavinys n-matėje erdvėje
su m ribojimų, tai
leistinų bazinių sprendinių (viršūnių) skaičius
ne didesnis negu
![]() . Tarkime, n = 2m , tada viršūnių skaičių
galima aproksimuoti
. Tarkime, n = 2m , tada viršūnių skaičių
galima aproksimuoti ![]() ir kai n =
100, tai viršūnių skaičius lygus
2100~ 1030 [1;4].
ir kai n =
100, tai viršūnių skaičius lygus
2100~ 1030 [1;4].
Nors augant
uždavinio dydžiui,
blogiausiu atveju uždavinio
sprendimo simplekso algoritmu laikas auga eksponentiškai, kyla
svarbus klausimas, ar
egzistuoja algoritmai, kurie
blogiausio atvejo požiūriu
paprastesni negu simplekso
algoritmas juolab, kad
daugeliui praktinių uždavinių
sprendimo laikas auga
ne greičiau negu
2m.
Elipsoidų metodas
remiasi visai kitomis idėjomis
nei simplekso algoritmas. Elipsoidų metodo žingsnių skaičius, augant uždavinio
dydžiui auga polinominių
greičiu, t.y. metodas priklauso polinominio sudėtingumo klasei. Šiuo požiūriu elipsoidų metodas žymiai pranašesnis už
eksponentinio sudėtingumo
klasei priklausantį simplekso algoritmą.
Elipsoidų algoritmas
skirtas griežtų tiesinių
nelygybių sistemoms spręsti.
Tegul nagrinėjama nelygybių
sistema pažymima AX < B. Inicializavimo žingsnyje sukuriamas pradinis
elipsoidas X0 , kuris apima nelygybių
sistemos sprendinių aibę
T arba jos
dalį (jei aibė neapibrėžta), k-
tajame algoritmo žingsnyje
tikrinama, ar hiperboloido Xk-1 centras vk patenkina nelygybių
sistemą. Jei taip,
tai uždavinys išspręstas.
Jei ne, nustatoma
nelygybė, kuri yra
nepatenkinama:
![]() .
.
Per elipsoido centrą
pravesta hiperplokštuma lygiagreti
hiperplokštumai ![]() dalija hiperelipsoidą pusiau ir T priklauso
hiperelipsoido pusei, kuri
patenkina nelygybę
dalija hiperelipsoidą pusiau ir T priklauso
hiperelipsoido pusei, kuri
patenkina nelygybę ![]() Nesunku sukonstruoti hiperelipsoidą,
kuris apima padalinto
hiperelipsoido pusę ir
kurio hipertūris ženkliai mažesnis
už padalinto hiperelipsoido tūrį.
Remiantis šia savybe
sudaromas hiperelipsoidas Xk . k := k+1 žingsnis
kartojamas ir po baigtinio
žingsnių skaičiaus bus gautas
nelygybių sistemos sprendinys,
tačiau svarbu pažymėti
jog algoritmui būtina
papildoma sustojimo sąlyga [1; 4.].
Nesunku sukonstruoti hiperelipsoidą,
kuris apima padalinto
hiperelipsoido pusę ir
kurio hipertūris ženkliai mažesnis
už padalinto hiperelipsoido tūrį.
Remiantis šia savybe
sudaromas hiperelipsoidas Xk . k := k+1 žingsnis
kartojamas ir po baigtinio
žingsnių skaičiaus bus gautas
nelygybių sistemos sprendinys,
tačiau svarbu pažymėti
jog algoritmui būtina
papildoma sustojimo sąlyga [1; 4.].
Nepaisant to, kad elipsoidų algoritmas blogiausio
atvejo sudėtingumo kriterijaus
požiūriu yra žymiai geresnis
už simplekso algoritmą,
jis parodė, kad sprendžiant
praktinius uždavinius jis
sunkiai konkuruoja su simplekso algoritmu. Pagrindinė priežastis
ta, kad simplekso
algoritmo žingsnis realizuojamas žymiai paprastesniais skaičiavimais negu elipsoidu
algoritmo žingsnis. Ne
ką mažiau svarbu
tai jog praktiniuose uždaviniuose
simplekso algoritmo vykdomų
žingsnių skaičius daug mažesnis
negu blogiausiu atveju,
o elipsoidų algoritmui tokia
savybė nėra būdinga.
Praėjus keliems metams po elipsoidų metodo
paskelbimo, N. Karmarkar
pasiūlė kitokią idėją,
pradėjusią naują taip
vadinamų vidinio taško
metodų kryptį.
Karmarkar'o metodo sudėtingumą
aprašančio polinomo laipsnis žemesnis
negu elipsoidų metodo sudėtingumą aprašančio polinomo laipsnis, be to
šis metodas sėkmingai
konkuravo su simplekso algoritmu sprendžiant
praktinius uždavinius [1; 4].
Karmarkar'o metodas tiesiogiai tinka
specialiam tiesinio programavimo uždavinio atvejui, kai
visų išskyrus vieną, ribojimų dešiniosios
pusės lygios nuliui. Išskirtinis
ribojimas yra x1 + x2
+ …xn = 1. Be to,
reikalaujama, kad
leistinajai sričiai priklausytų
taškas ![]() kur I - vienetinis
vektorius.
kur I - vienetinis
vektorius.
Tiesinio programavimo uždavinys vadinamas Karmarkar’o
standartiniu uždaviniu, jei
leistinoji sritis yra apibrėžta šitaip:
![]() (2.36)
(2.36)
Kur K –politopas, vadinamas standartiniu n-1 matavimo simpleksu. Jo išraiška
yra ![]() o taškas
o taškas ![]() jo centru. A-sveikųjų skaičių matrica. VÎ G, tikslo funkcijos
koeficientai C yra sveikieji
skaičiai ir tikslo funkcijos reikšmės CX neneigiamos, kai XÎ G. Keliamas
uždavinys- rasti srities
G tašką, kuriame tikslo funkcijos reikšmė lygi
nuliui arba nustatyti, kad toks
taškas neegzistuoja.
jo centru. A-sveikųjų skaičių matrica. VÎ G, tikslo funkcijos
koeficientai C yra sveikieji
skaičiai ir tikslo funkcijos reikšmės CX neneigiamos, kai XÎ G. Keliamas
uždavinys- rasti srities
G tašką, kuriame tikslo funkcijos reikšmė lygi
nuliui arba nustatyti, kad toks
taškas neegzistuoja.
Bendrai paėmus vidinio
taško metodus jų tyrimas
ir sėkmingas taikymas
gerokai išplėtė
optimizacijos metodų taikymo
sritį, taip pat
davė impulsą ir
simplekso algoritmo tobulinimui.
2.5.1 TP uždavinių sprendimo metodo parinkimas
Iš
aukščiau aptartų tiesinio
programavimo uždavinių sprendimo
metodų reikia parinkti
tinkamą AR-ABS modelio
paklaidos absoliutiniais didumais
sumos minimizavimui. Iš
pirmo žvilgsnio norėtųsi
rinktis ne eksponentinio, bet polinominio
sudėtingumo metodą t.y.
elipsoidų arba vidinio taško
metodų klasės Kalmarkar’o
algoritmą.
Elipsoidų
metodas nors ir
yra polinominio sudėtingumo, tačiau praktinių uždavinių
sprendime nepranoksta simplekso
algoritmo, be to
sprendžiant tiesinio programavimo uždavinius elipsoidų
metodu, ribojimai aprašomi
griežtomis tiesinėmis
nelygybėmis, o mūsų
formuluojamame uždavinyje nelygybės
yra negriežtos.
Kiek
sunkiau nuspręsti dėl Karmarkr’o algoritmo kuris pasižymi
žemesniu metodo sudėtingumą
aprašančiu polinomo laipsniu.
Šio metodo trūkumas
tas jog norint spręsti
modulio ženklo problemą reiktų pateikti naują optimizavimo uždavinio, o tiksliau
apibrėžimo srities formulavimą, tokį, kad visos
ribojimų dešiniosios pusės,
išskyrus, vieną , būtų
lygios nuliui.
Sprendžiant tiesinio programavimo uždavinius
simplekso algoritmu, ribojimai
užrašomi įprastomis
nelygybėmis ir be
jokių papildomų reikalavimų
kaip tai yra
elipsoidų ar Karmarkar’o
algoritme. Atsižvelgus ir į
tai, kad praktinių uždavinių sprendimo
laikas simplekso algoritmu
auga ne greičiau
nei 2m, nuokrypių
absoliutiniais didumais sumos minimizavimui pasirinktas
simplekso algoritmas.
Išanalizavus teorinį optimizavimo uždavinio
sprendimo metodo pasirinkimą svarbu pažymėti ir
tai, jog praktinį
pasirinkimą įtakojo ribotas
optimizavimo įrankių
(programinės įrangos) pasirinkimas. Realiai pasirinkimas gal ir
nėra mažas, tačiau
tokios įrangos, ypač
galinčios spręsti didelius
optimizavimo uždavinius, svarba
praktinėje ekonomikoje
diktuoja pinigais išreikštą
kainą.
Sugrįžus
prie nuokrypių absoliutiniais didumais sumos minimizavimo uždavinio siekiant
didesnio aiškumo formules (2.26), (2,27), (2.28),
(2,29) užrašysime išskleista forma:
Tikslo funkcija-

Ribojimai-
![]()
![]()
![]() kai
kai
u – tai fiktyvus kintamieji,
kurie turi būti lygūs 0,
kad būtų patenkintos (2.27) ir (2.28) arba (2.27’)
ir (2.28’) sąlygos.
2.6 AR-ABS ir ARMA modelių teorinis palyginimas
Analizuojant formalias
šių modelių išraiškas
nesunkiai pastebėsime jog abu
šie modeliai panašūs tuo, kad
turi auto regresijos dalį. Esminis šių modelių skirtumas - nuokrypių
minimizavimui taikomas
metodas. Šių modelių
skirtumai pateikti lentelėje
Nr. 1
Lentelė Nr.1
|
ARMA |
AR-ABS |
|
|
Neturi; |
|
|
Minimizuojama nuokrypių absoliutiniais
didumais suma: |
|
Optimizavimo uždavinys susiveda į tiesinių
lygčių sistemos sprendimą; |
Optimizavimo uždavinys susiveda į nelygybių sistemos sprendimą; |
|
|
Koeficientai a sudaromi iš dviejų dėmenų: |
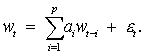
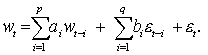
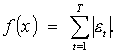
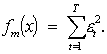
2.7 Auto regresijos pritaikymas klasifikavimo uždaviniuose
AR modeliai (tuo pačiu ir AR -ABS) su išorinių faktorių įvertinimu gali būti taikomi įvertinti tiesinės regresijos parametrams. Skirtumas tas jog tokiu atveju t - žymės nebe laiko momentus, bet stebimų pavyzdžių kiekį, o AR modelio parametras p – bus lygus nuliui, nes stebimi pavyzdžiai nepriklauso vienas nuo kito ( t.y. i-tasis pavyzdys nepriklauso nuo i-1, i-2 ir t.t.). Tokiu atveju pagrindinis parametras
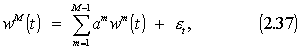
wM(t), gali būti išreiškiamas per išorinius parametrus
(faktorius) w(t) = (wm(t), m=1,....,M-1) ir išraiška (2.30) keičiama į :
kur t = 1,…,T-1 žinomi pavyzdžiai (žinoma kokiai klasei jie priklauso), o T – pavyzdys, kurio žinome išorinių parametrų reikšmes ir pagal jas spręsime, kuriai klasei priklauso šis pavyzdys. Išraišką (2.37) galima suvesti į vienmatį atvejį:
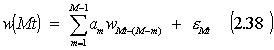
2.7.1 Optimizavimo uždavinio sudarymas
Toliau
tokiu pat principu kaip ir aukščiau
išanalizuoto AR-ABS teorinio modelio sudaryme mūsų tikslas minimizuoti
visų nuokrypių moduliu sumą (žiūr. (2.26’), (2.27’), (2.28’), (2.11)
išraiškas). Tačiau programinėje algoritmo realizacijoje
optimizavimo uždavinio formulių
išreiškimas šiek tiek skiriasi.
Tikslo
funkcija-

Ribojimai-


Kai t kinta nuo 1 iki T-1.
Išsprendus
optimizavimo uždavinį randama M-1 a koeficientų.
2.7.2 Klasifikavimas
Klasifikavimo uždavinys skiriasi nuo prognozavimo tuo, jog čia reikės ne vieno a koeficientų rinkinio. Reikia pabrėžti jog optimizavimo uždavinys turės būti sprendžiamas ir randama tiek a koeficientų rinkinių, kiek yra klasių, pvz. Modifikuojant modelį buvo naudojami tokie duomenys:
Lentelė Nr. 2
|
! |
681 |
-84 |
-256 |
-313 |
-6 |
-99 |
-339 |
200 |
48 |
21 |
-8 |
19 |
-51 |
-12 |
|
! |
739 |
-107 |
-224 |
-291 |
-192 |
-273 |
-320 |
190 |
42 |
18 |
-10 |
0 |
-47 |
-9 |
|
! |
704 |
3 |
-316 |
-307 |
-28 |
-76 |
-361 |
206 |
45 |
16 |
-1 |
9 |
-56 |
-15 |
|
? |
436 |
-58 |
-129 |
-64 |
-58 |
-24 |
-135 |
266 |
101 |
23 |
13 |
-32 |
-85 |
-43 |
|
? |
413 |
-41 |
-128 |
-46 |
-55 |
-10 |
-132 |
258 |
90 |
41 |
6 |
-10 |
-39 |
-2 |
|
? |
413 |
-20 |
-120 |
-53 |
-62 |
-10 |
-148 |
259 |
86 |
25 |
-8 |
-9 |
-53 |
5 |
|
( |
576 |
226 |
-204 |
-80 |
-154 |
-168 |
-190 |
204 |
-8 |
9 |
-7 |
-10 |
-16 |
-27 |
|
( |
602 |
180 |
-186 |
-86 |
-164 |
-164 |
-194 |
204 |
-2 |
8 |
-6 |
-8 |
0 |
-29 |
|
( |
658 |
258 |
-192 |
-44 |
-140 |
-156 |
-188 |
224 |
-3 |
-5 |
-16 |
-19 |
-16 |
-27 |
- kur eilutė – tai pavyzdys, o pirmo stulpelio elementas žymi klasę, kuriai priklauso pavyzdys. Akivaizdu jog pateiktame duomenų fragmente išskiriamos 3 klasės. Ieškant a koeficientų pirmajai klasei, reikės taip transformuoti duomenis , kad w(Mt) reikšmės, kur t pavyzdys atitinka „!“ klasę būtų lygios 1, o visos kitos w(Mt) =0; ir tik tuomet spręsti optimizavimo uždavinį.
Lentelė Nr. 3
|
1 |
681 |
-84 |
-256 |
-313 |
-6 |
-99 |
-339 |
200 |
48 |
21 |
-8 |
19 |
-51 |
-12 |
|
1 |
739 |
-107 |
-224 |
-291 |
-192 |
-273 |
-320 |
190 |
42 |
18 |
-10 |
0 |
-47 |
-9 |
|
1 |
704 |
3 |
-316 |
-307 |
-28 |
-76 |
-361 |
206 |
45 |
16 |
-1 |
9 |
-56 |
-15 |
|
0 |
436 |
-58 |
-129 |
-64 |
-58 |
-24 |
-135 |
266 |
101 |
23 |
13 |
-32 |
-85 |
-43 |
|
0 |
413 |
-41 |
-128 |
-46 |
-55 |
-10 |
-132 |
258 |
90 |
41 |
6 |
-10 |
-39 |
-2 |
|
0 |
413 |
-20 |
-120 |
-53 |
-62 |
-10 |
-148 |
259 |
86 |
25 |
-8 |
-9 |
-53 |
5 |
|
0 |
576 |
226 |
-204 |
-80 |
-154 |
-168 |
-190 |
204 |
-8 |
9 |
-7 |
-10 |
-16 |
-27 |
|
0 |
602 |
180 |
-186 |
-86 |
-164 |
-164 |
-194 |
204 |
-2 |
8 |
-6 |
-8 |
0 |
-29 |
|
0 |
658 |
258 |
-192 |
-44 |
-140 |
-156 |
-188 |
224 |
-3 |
-5 |
-16 |
-19 |
-16 |
-27 |
Turint a koeficientų K rinkinių, kur K- klasių kiekis, bei naują pavyzdį apibrėžiančių faktorių vertes w1,.....,wM-1 skaičiuosim wM reikšmes.
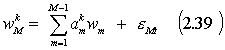
![]() - pavyzdžio priklausomumo k-tąjai klasei
reikšmė;
- pavyzdžio priklausomumo k-tąjai klasei
reikšmė;
![]() - a rinkinys k-tąjai klasei;
- a rinkinys k-tąjai klasei;
k = 1,....,K.
Visos apskaičiuotos reikšmės idealiu atveju turėtų pakliūti į intervalą [0;1], tačiau realiai jos gali būti tiek didesnės už 1, tiek mažesnės už 0.
2.7.3 Klasifikavimo taisyklės parinkimas
Kai jau turim priklausomybės kiekvienai klasei
reikšmes, reikia nuspręsti pagal kokią taisyklę išrinksim kuriai klasei vis tik
priklauso naujasis pavyzdys.
Pats primityviausias būdas būtų paprasčiausias
reikšmių apvalinimas iki 1 arba 0.
Sekančiu etapu pavyzdys bus priskiriamas tai klasei, kur priklausomumo
tai klasei suapvalinta reikšmė bus lygi vienetui. Tais atvejais kai gausime
daugiau nei vieną reikšmę = 1 priimsime
jog modelis pavyzdžio nesuklasifikavo, t.y. net nežinant, kokiai pavyzdys
iš tikrųjų klasei priklauso
galima teigti jog modelis neteisingai
klasifikavo.
![]()
Kitas būdas – gautas
priklausomumo reikšmes sunormalizuoti į intervalą [0; 1] pagal formulę :
O toliau gautas reikšmes tokiu pat principu
apvalinti iki 1 arba 0.
Galimas ir kitas samprotavimo būdas – normalizavimu
eliminuojama dalis svarbios informacijos, kaip pvz.: reikšmė 1,1 reiškia labai stiprų priklausymą kokiai tai
klasei, analogiškai -0,1 stiprų nepriklausymą. Todėl iškyla
klausimas ar tikrai reiktų duomenis normalizuoti.
Svarbu pastebėti, jog ne visada gali tenkinti
paprasčiausias apvalinimas, pvz.: toks apvalinimas 0,51 → 1, o 0,49 → 0 gali būti nepakankamai
griežtas. Tokiu atveju galima įvesti intervalą,
į kurį pakliuvus reikšmė būtų apvalinama į vieną ar kitą pusę. Pvz.: turime intervalo ilgį l = 0,4.
![]() 0 0,5 1
0 0,5 1
![]()
![]() d1
l/2 1- l/2 d2
d1
l/2 1- l/2 d2
Jeigu reikšmė paklius į intervalą [1-l/2; d2] bus apvalinama į 1, o jei į intervalą [d1; l/2] bus apvalinama į 0. Jei reikšmė paklius į intervalą (1-l/2; l/2) nebus sprendžiama apie pavyzdžio priklausymą tai klasei.
Toks pasitikėjimo intervalo keitimas gali
būti taikomas tiek normalizuotiems, tie nepakeistiems rezultatams.
Kuomet
reikia suklasifikuoti nedaug
pavyzdžių, gali pasikliauti
žmogaus intuicija pateikiant
jam tik konkretaus naujo pavyzdžio
priklausomumo kiekvienai klasei
reikšmes.
3
PROGRAMINĖ
REALIZACIJA
Siekiant kuo
efektyviau vizualizuoti uždavinį, išnaudoti interneto privalumus buvo
pasirinkta JAVA programavimo kalba.
Daugelį principų
JAVA programavimo kalba yra paveldėjusi iš C++, kurios pagrindu ji ir buvo sukurta.
Kaip ir daugelis objektiškai orientuotų programavimo kalbų, JAVA turi klasių
bibliotekas, kurios suteikia pagrindinius programavimo įrankius. JAVA taip pat
įtraukia bendruosius interneto protokolus ir daugelį kitų dalykų, kurių dėka
išpopuliarėjo ši kalba.
Nepriklausomumas
nuo platformos, t.y. galimybė lengvai programą perkelti iš vienos kompiuterio
sistemos į kitą, yra vienas didžiausių JAVA privalumų kuriant ir realizuojant
tokius bei panašius projektus. JAVA kalbos klasių struktūra sudaro galimybę
lengvai sukurti kodą, pernešamą nuo vienos platformos prie kitos.
AR-ABS modelio
programa ir jos sudedamieji moduliai yra parašyti JAVA programine kalba, todėl
ji gali būti vykdoma kaip JAVA „applet’as“ arba kaip JAVA vykdomoji programa (JAVA „application“). Privalumas vykdant
programą kaip JAVA „applet’ą“ yra akivaizdus, ji gali būti pasiekiama per internetą
ir paleidžiama vykdyti iš Html failo. Šią programą galima
išplėsti, prijungiant naujus optimizavimo modelius, panaudojant pačias
naujausias JAVA programinės kalbos savybes.
3.1
Standartinių
elementų bei išorinių programų naudojimas
Tiesinio programavimo uždavinio sprendimui
naudojama Michel Berkelar sukurta programa – „Lp_solve“. Tai geriausia
internete esanti nekomercinė
tokio pobūdžio programa. Ji sprendžia didelius iki 30 tūkstančių kintamųjų turinčius
tiesinio programavimo uždavininius [7]. Pats autorius programą
realizavo C- programavimo kalba.
Šiuo metu internete yra JAVA, Perl programavimo kalbomis perrašyta
programa. Siekiant užtikrinti
programos veikimą interneto aplinkoje pasirinkta „Lp_solve“ JAVA versija.
Kuriant grafinę
vartotojo sąsają naudojami
standartiniai grafiniai elementai tokie
kaip pranešimai, langai ir kiti
pritaikant juos programai.
3.1.1 „Lp_solve“ pritaikymo ir naudojimo problematika
Visi „Lp_solve“ JAVA kalba klasių tekstai buvo sukurti automatinio konvertavimo iš C būdu [8]. Konvertavimas yra iš C į JAVA yra problematiškas ypač dėl C kalboje naudojamų rodyklių, todėl gali atsirasti nesutapimų tarp „Lp_solve“ C ir JAVA versijų pateikiamų tiesinio programavimo uždavinių sprendinių. Tam, kad preliminariai ištirti „Lp_solve“ JAVA versijos patikimumą keli TP uždaviniai buvo pabandyti spręsti „Lp_solve“ JAVA, „Lp_solve“ C versijomis bei MATLAB paketu. Tyrimas parodė jog šiais trim metodais sprendžiant tą patį uždavinį gaunami tokie pat rezultatai. Šio tyrimo rezultatai pateikiami priede Nr. 1.
Apibendrinant, realizuotas AR-ABS modelis
JAVA programavimo kalba.
Programa nesudėtingai
paleidžiama per interneto naršyklę.
Programoje realizuota:
Galimybė tirti
AR-ABS modelį, ieškoti optimalų
atsimenamų į praeitį momentų
kiekį, prognozuoti ne tik
vieną žingsnį į ateitį,
bet ir pasinaudojant
turimais duomenimis įvertinti
vidutinę daromą modelio paklaidą
prognozuojant vieną žingsnį
į ateitį ar norimą
kiekį žingsnių, kiekviename
žingsnyje priimant, jog turime
realių duomenų seką iki pat
prognozuojamo momento. Realizuota
galimybė prognozuoti visą eilę
momentų į ateitį ir taip pat
įvertinti daromą modelio
paklaidą. Įvesta AR-ABS
modelio modifikacija, bei realizuotos papildomos sprendimų
priėmimo metodikos
leidžiančios AR-ABS modelio
pagalba spręsti ne tik prognozavimo, bet ir diagnozavimo uždavinius.
Programos įdiegimo ir naudojimo aprašymas pateiktas Priede Nr. 2.
AR-ABS modelio JAVA pradinės programinės realizacijos testavimui
lygiagrečiai AR-ABS modelis
buvo realizuotas ir MATLAB paketu.
Eksperimentiniam AR-ABS modelio tyrimui bus
naudojama JAVA programavimo kalba realizuota
programa. AR-ABS ir ARMA
modelių palyginimui bus naudojami tie patys duomenys ir tos pačios duomenų
imtys. Skaičiavimai ARMA
modeliu bus atliekami su
prof. J. Mockaus realizuota ARMA modelio programa (C kalba).
4 MODELIŲ EKSPERIMENTINIS TYRIMAS
4.1 ARMA metodo tyrimas
ARMA metodas
yra plačiai taikomas
ir neblogai ištirtas. Analizuojamuose darbuose
jis, o tiksliau jo daroma paklaida
prognozuojant buvo lyginama su Random Walk metodu. Pastarajame
metode prognozė priklauso nuo
esamos reikšmės ir baltojo
triukšmo et. Šių modelių lyginimas
argumentuojamas tuo, jog Random Walk (RW) modelis yra atskiras ARMA
modelio atvejis kai
q =0, p=0
ir a1 =1, o
tuo pačiu ir labai
paprastas, be to
RW atitinka atsitiktines laiko eilutes, kadangi
et tarpusavyje nepriklausomi dydžiai.
Žemiau esančioje
lentelėje pateikti ARMA
ir RW modelių prognozavimo rezultatai.
Lentelė Nr. 4
|
Nr. |
Duomenys |
Delta ARMA% |
Mean ARMA |
Mean RW |
|
1 |
$/£ |
-0,1779 |
0,1145 |
0,1143 |
|
2 |
DM/$ |
-0,0119 |
0,1092 |
0,1092 |
|
3 |
Yen/$ |
-1,0860 |
6,3690 |
6,3006 |
|
4 |
Fr/$ |
-0,3029 |
0,4285 |
0,4272 |
|
5 |
AT/T |
-1,3750 |
4,5540 |
4,4922 |
|
6 |
Intel Co |
0,2814 |
20,52 |
20,58 |
|
7 |
London Stock Exch. |
-0,5107 |
275,1 |
273,7 |
|
8 |
Call Center |
30,7600 |
845,3 |
1220,8 |
Pirmose keturiose eilutėse pateikti valiutų kursų
prognozavimo rezultatai,
sekančiose trijose -
tam tikrų kompanijų
akcijų kursų biržos
uždarymo momentu, Londono
biržos indekso prognozavimo rezultatai ir
paskutinėje eilutėje užsakymų
priėmimo telefonu kiekio
prognozavimo rezultatai [3;6].
Mean RW -
tai vidutinė prognozės
paklaida prognozuojant RW metodu, Mean ARMA - tai
vidutinė prognozės paklaida
prognozuojant ARMA modeliu,
Delta ARMA tai procentinė (RW –ARMA)/ RW išraiška parodanti kiek
procentų ARMA modeliu
prognozės paklaida mažesnė
už Random Walk.
Šie rezultatai buvo
skaičiuojami prie optimalių
p ir q parametrų apibrėžiančių ARMA
modelį (t. y. tokių, su
kuriais gaunama mažiausia
prognozavimo paklaida).
Analizuojant rezultatus
pateiktus lentelėje, kur
teigiama Delta ARMA
parodo jog ARMA
modelis daro mažesnes
paklaidas nei RW, o
neigiama reikšmė reiškia RW
privalumą, galima pastebėti
jog beveik visas
finansines eilutes ARMA
modelis prognozuoja šiek
tiek prasčiau nei RW (labai blogi
rezultatai gauti prognozuojant Hermis banko akcijų
kursą) ir tik Intel Co akcijų
kursą prognozuoja šiek
tiek geriau. Tuo
tarpu „Call Center“
duomenis ARMA metodas
prognozuoja net 30,8% geriau
nei RW. Tai
tik patvirtina, jog
finansiniai rodikliai yra
sunkiai prognozuojami. Tai
ko gero įtakoja
jų pačių priklausomumas nuo
prognozės, nuo to
kaip žmonės įsivaizduoja jų pasikeitimą ateityje.
4.2 AR-ABS modelio tyrimo metodika
Tyrimui bus
naudojami tie patys
duomenys su kuriais
buvo atliktas RW ir ARMA modelių
prognozavimo rezultatų palyginimas. Išsamesniam tyrimui pasirinkti
„Call Center“ duomenys žiūr.
pav. Nr. 1 , su kuriais
prognozuojant ARMA modelio
pagalba buvo gauti
geri rezultatai ir AT&T kompanijos akcijų
kurso kitimo duomenys,
su kuriais prognozuojant ARMA modelio pagalba
buvo gauti vieni
iš blogesnių rezultatų.
Šie duomenys skiriasi savo charakteristika:
1.
„Call Center“ duomenys, tai
seka reikšmių kiek kiekvieną dieną
buvo priimta skambučių, prognoze
kiek rytoj bus priimta
skambučiu neturi įtakos
kiek iš tikrųjų jų
rytoj bus, taigi tai
duomenys, kurie nepriklauso
nuo pačios prognozės;
2.
AT&T kompanijos
kurso duomenys - tai
finansiniai duomenys, kurie yra
sunkiai prognozuojami ir
pagrindinė priežastis ta,
jog ateitis priklauso
nuo prognozės, nuo to ką
mes manome ateityje būsiant.
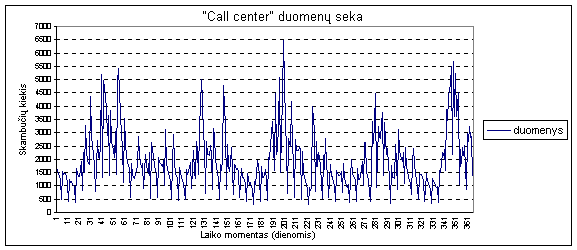
1 pav. „Call Center“ duomenys

2 pav. AT&T kompanijos duomenys
Galimi įvairūs duomenų paklaidos
įvertinimui surinkimo būdai:
·
Prognozuoti vieną žingsnį
į priekį;
·
Prognozuoti n žingsnių į priekį
neperskaičiuojant a koeficientų,
kiekvienam žingsnyje
priimant, jog turime realių duomenų seką iki pat prognozuojamo momento;
·
Prognozuojant n žingsnių į
priekį kiekvieną kartą
perskaičiuojant a koeficientus;
·
Prognozuoti n žingsnių į
priekį, visuose n žingsnių
išskyrus pirmąjį, kaip
dalį duomenų imant
ne realius, o
suprognozuotus duomenis.
Visi
šie būdai paklaidos
įvertinimui nėra lygiaverčiai
pvz.: būtų per daug drąsu
suradus a
koeficientus vieną kartą
prognozuoti ir pagal gautą
paklaidą spręsti apie modelio privalumus ir trūkumus, todėl
bus remiamasi rezultatais
gautais prognozuoti n žingsnių į
priekį neperskaičiuojant a koeficientų, kiekviename
žingsnyje priimant, jog turime
realių duomenų seką iki pat
prognozuojamo momento. Kaip
ir tiriant ARMA
modelį taip ir
AR-ABS duomenys bus
skiriami į tris
lygias dalis:
1.
Pirma duomenų dalis bus
naudojama a
koeficientų radimui;
2.
Antra duomenų dalis
optimalaus parametro p
nustatymui, t.y. kiek
laiko momentų į
praeitį reikia atsiminti, kad
modelis darytų mažiausią paklaidą.
3.
Trečios dalies duomenys
bus naudojami modelio daromos
paklaidos nustatymui, t.y.
bus prognozuojama tariama ateitis nors realiai turima
to laiko intervalo
duomenų seka. To
pasėkoje bus galima
įvertinti modelio duodamą
prognozės paklaidą bei
jo elgesį esant
dideliems duomenų svyravimams.
Modelį galima
tirti tokiais aspektais:
o
Duomenų imties naudojamos
a koeficientų
radimui įtaka atsimenamų į praeitį žingsnių kiekiui,
o tuo pačiu ir paklaidai;
o
Optimalus atsimenamų į praeitį žingsnių kiekis;
o
a koeficientų įtaka
prognozei;
o
Išorinių faktorių
įvertinimo įtaka prognozei tiek ARMA,
tiek AR-ABS modeliais;
o
Prognozavimas daugiau nei vieno žingsnio į priekį ARMA ir AR-ABS
modeliais;
4.3 Duomenų imtis
Siekiant ištirti
duomenų imties įtaką
optimalaus atsimenamų į praeitį
momentų kiekiui p,
bei prognozavimo paklaidai, eksperimentas buvo atliktas su „Call
Center“ priimamų skambučių kiekio
duomenimis ir AT&T kompanijos akcijų kurso kitimo
duomenimis.
Imtis buvo didinama kas 40 laiko momentų, prognozuojama 40
žingsnių į priekį
(neperskaičiuojant a koeficientų)
ir ieškoma vidutinė
modelio paklaida atsimenant
skirtingą laiko momentų
į praeitį kiekį.
Pvz. turime 80 laiko
momentų eilutę, randame
a koeficientus, kai atsimenamų į praeitį momentų kiekis
lygus 1, tuomet prognozuojam skambučių kiekius 81, 82, …….120 laiko momentais ir
lygindami su realiais randame vidutinę daromą modelio paklaidą
, tokius pat skaičiavimus
atliekame kuomet atsimenamų į praeitį
momentų kiekis lygus 2,
3 ….40. Toliau padidiname duomenų imtį iki 120 ir
kartojame aprašytą tyrimo
algoritmą.
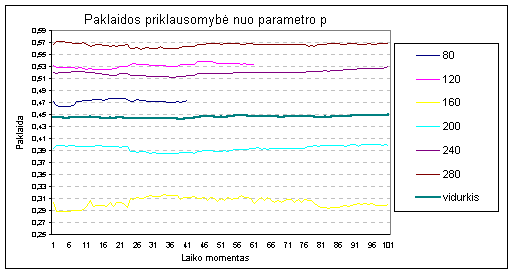
Tyrimo su Call center duomenimis
rezultatai pateikti žemiau esančiame paveikslėlyje.

3 pav. Paklaidos priklausomybė naudojant „Call Center“ duomenis
Paveikslėlyje
kiekviena kreivė apibrėžia paklaidos kitimą kintant atsimenamų į praeitį momentų
kiekiui esant tam tikrai duomenų
imčiai (80, 120,160 ir t.t.).
Analizuojant grafiką galima
teigti jog optimalus parametras p
turėtų pakliūti į
intervalą [7-36] nepriklausomai nuo duomenų imties,
taip pat galima stebėti tendenciją
jog imant ilgesnį duomenų intervalą koeficientų
optimizavimui AR-ABS modelis
prognozuoja su mažesne paklaida,
be to natūralu jog visad
norėsis maksimaliai išnaudoti
turimus duomenis ir realybėje
koeficientų a optimizavimui bus imama kiek ymanoma
didesnė duomenų imtis.
Tyrimo su AT&T
kompanijos duomenimis rezultatai
pateikti žemiau
esančiame paveikslėlyje.
4 pav. Paklaidos priklausomybė naudojant AT&T kompanijos duomenis
Lyginant su „Call Center“ duomenų
rezultatais finansinių
duomenų tyrimo metu gauti
prastesni rezultatai,
galima išskirti intervalą
nuo 2 iki 44 į kurį
turėtų pakliūti optimalaus atsimenamų
į praeitį laiko momentų
kiekis, tačiau kaip matyti
iš grafiko nėra aiškiai išsiskiriantis. Taip pat atliekant tyrimą su
AT&T
kompanijos akcijų kurso
duomenimis nebėra tendencijos, jog imant
ilgesnį duomenų intervalą koeficientų optimizavimui AR-ABS, modelis prognozuoja su mažesne paklaida.
Sunku
vienareikšmiškai įvertinti
optimalaus parametro p (atsimenamų į praeitį momentų kiekio)
priklausomybę nuo laiko eilutės ilgio. Kaip parodė tyrimo su „Call Center“ duomenimis
rezultatai aiškios priklausomybės nėra,
t.y. nepriklausomai nuo duomenų imties intervalas į kurį pakliūva
optimalus parametras p stipriai
nesikeičia.
Apibendrinus galima pateikti tokias
išvadas:
§
Optimalus
parametras p kiekvienai
laiko eilutei (o tuo
labiau skirtingų duomenų laiko
eilutėms) bus kitoks;
§
Didinat
duomenų, pagal kuriuos ieškomi a koeficientai, imtį
mažėja AR- ABS modelio daroma paklaida.
Kaip parodė AT&T kompanijos akcijų kurso
prognozavimas AR-ABS modeliu, paskutinioji išvada
nebūtinai galios visokiems, o ypač
finansinams duomenims.
4.4 Optimalus duomenų atsiminimo kiekis
Kadangi nėra aiškios priklausomybės tarp
duomenų imties ir optimalaus parametro p -
tokio į praeitį atsimenamų duomenų kiekio, prie kurio prognozuojant
modelis daro mažiausią paklaidą , tolimesniuose tyrimuose a koeficientų
radimui bus naudojama kiek įmanoma
didesnė duomenų imtis,
laikantis 4.2 poskyryje
aprašyto duomenų imties dalinimo į tris dalis (a
koeficientų radimui, p parametro
optimizavimui ir prognozavimo paklaidos įvertinimui ) principo.
Atliekant tyrimą su „Call Center“ duomenimis
buvo imama 120 laiko momentų
laiko eilutė a koeficientų
radimui ir tiek pat momentų prognozuojama vidutinės paklaidos
radimui.

5 pav. Optimalus duomenų atsiminimo kiekis „Call Center“ duomenims
Mažiausia
AR-ABS modelio prognozės vidutinė
paklaida daroma kuomet
atsimenamų į praeitį laiko momentų
kiekis 19 (paklaida 620,95 skambučių).
Jei reikalautumėm jog
paklaida nebūtinai būtų minimali, bet
ne didesnė nei 660 skambučių
tuomet optimalus duomenų atsiminimo
kiekis turėtų būti iš intervalo 7- 25.
Atliekant tyrimą su
AT&T
kompanijos duomenimis buvo
taip pat imama 153 laiko momentų laiko eilutė.
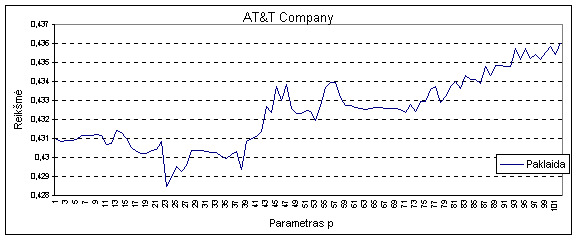
6 pav. Optimalus duomenų atsiminimo kiekis AT&T kompanijos duomenims
Mažiausia
AR-ABS modelio prognozės vidutinė
paklaida AT&T duomenims daroma kuomet atsimenamų į praeitį laiko momentų kiekis 23 ( paklaida 0,4285 vnt.). Jei reikalautumėm jog
paklaida nebūtinai būtų minimali, bet
ne didesnė nei 0,43 tuomet
optimalus duomenų atsiminimo
kiekis turėtų būti iš intervalo 23- 27.
Nors
galima rasti bendrą intervalą ir vieniems ir
kitiems duomenims, kad optimalus
atsimenamų į praeitį duomenų kiekis pakliūtų į jį, tačiau
šis intervalas gali būti per
daug ilgas, kad modelis ir su vienais ir su
kitais duomenimis prie to paties
atsimenamų į praeitį parametrų
kiekio duotų minimalią
(ar arti jos) paklaidą.
Apibendrinus galima pateikti tokias
išvadas:
§
Norint minimizuoti daromą
modelio prognozės paklaidą
, reikia skirtingiems duomenims rasti
savo optimalų atsiminimo į praeitį laiko momentų kiekį.
§
Atsimenamų į praeitį laiko momentų kiekiui artėjant prie laiko eilutės ilgio (pvz:
T=160, p=120) paklaidos
išaugs;
Lyginant
AR –ABS ir ARMA modelių
optimalius parametrus galime pateikti tokią rezultatų lentelę.
Beveik
visiems duomenims AR-ABS modelio
optimalus atsimenamų į praeiti laiko momentų kiekis yra didesnis nei ARMA
modeliu, žiūr. lentelė Nr. 5.
Tiesa, šioje lentelėje pateiktiems rezultatams
apskaičiuoti „Call Center“ skambučių kiekio
prognozei buvo naudojami ir
išoriniai duomenys. Plačiau
išorinių parametrų įtaka
optimalaus atsiminimo į praeitį duomenų kiekiui bus analizuojama atskirame poskyryje.
Lentelė Nr. 5
|
Nr. |
Duomenys |
ARMA p |
ARMA q |
AR-ABS p |
|
1 |
$/£ |
6 |
1 |
5 |
|
2 |
DM/$ |
9 |
2 |
48 |
|
3 |
Yen/$ |
9 |
2 |
22 |
|
4 |
Fr/$ |
4 |
2 |
48 |
|
5 |
AT/T |
3 |
2 |
23 |
|
6 |
Intel Co |
5 |
1 |
18 |
|
7 |
London Stock Exch. |
1 |
2 |
4 |
|
9 |
Call Center |
6 |
1 |
6 |
4.5 Koeficientų a įtaka prognozuojamai reikšmei
Norint ištirti, kaip a koeficientai
įtakoja prognozuojamą reikšmę
buvo atlikta eilė bandymų. Buvo pastebėta jog naudojant finansinius duomenis didžiausią įtaką
turi pirmasis koeficientas,
tai reiškia jog prognozuojant rytdienai mums bus labai svarbu kas buvo šiandien. Pirmasis koeficientas dažnai yra
artimas vienetui, o visi likę svyruoja apie
0 tačiau atsimenant vos ne visą duomenų
seką konvergavimas į 0 nėra
stebimas žiūr. Priedas Nr. 3. Atliekant tyrimą su AT&T
kompanijos duomenimis, kuomet imamas optimalus atsimenamų į praeitį momentų
kiekis, taip pat nėra aiškaus a koeficientų
konvergavimo į 0.

7 pav. Koeficientų a
įtaka prognozuojamai reikšmei naudojant
AT&T duomenis
Atliekant
tyrimą su kitos charakteristikos (nefinansiniais) „Call Center“ duomenimis
stebimi kitokie rezultatai. Čia
atsimenant vos ne visą
duomenų seką stebimas
stiprus svyravimas, kuomet imamas optimalus atsimenamų į praeitį momentų
kiekis a koeficientų įtaka
prognozei visiškai skiriasi nuo a koeficientų įtakos
finansinių duomenų
prognozei, tai kas buvo vakar neturi didžiausios įtakos. Kaip matyti iš žemiau pateikto
paveikslėlio vienodai didelę įtaką prognozei turi tiek tai, kas buvo
prieš 7 dienas ir tik po to kas
buvo vakar ir netgi padidinus laiko eilutės, pagal kurią sprendžiant optimizavimo uždavinį
randami a koeficientai, ilgį
dvigubai koeficientų įtaka beveik
nepasikeičia. Imant didesnį nei optimalų
atsimenamų į praeitį momentų kiekį
šių dviejų dienų įtaka taip pat beveik nesikeičia.
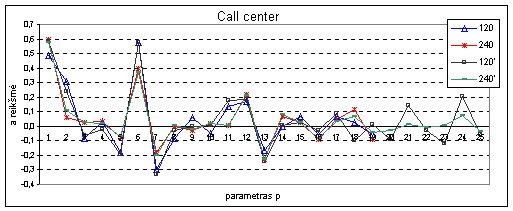
8 pav. Koeficientų a
įtaka prognozuojamai reikšmei naudojant
„Call Center“ duomenis
4.4 skyriuje buvo išsiaiškinta
jog naudojant AR-ABS modelį
beveik visiems duomenims
optimalus atsimenamų į praeitį momentų
kiekis yra didesnis nei naudojant ARMA modelį,
tačiau analizuojant a koeficientų įtaką finansinių duomenų prognozei,
AR-ABS modelis kaip ir ARMA
ne ką te nutolsta nuo Random Walk metodo, kuomet prognozuojama, kad rytoj bus taip
kaip šiandien. Tokią
išvadą galima pagrysti
tuo, jog pirmojo
a koeficiento, nulemiančio to kas buvo šiandien svarbą,
(jam apytiksliai esant
lygiam vienetui) įtaka yra
didžiausia, o visų kitų koeficientų įtaka nėra tokia
stipri.
Nefinansiniams
duomenis (nepriklausantiems nuo pačios prognozės) AR-ABS modelis gerai išskiria
pasikartojamumą, pvz.: „Call Center“
priimamų skambučių kiekis priklauso nuo savaitės dienos, todėl tokią pat didelę įtaką kaip pirmasis koeficientas turi ir šeštas
koeficientas.
4.6 Prognozė AR-ABS modeliu
Prognozės gerumą,
patikimumą geriausiai įvertins
daroma modelio paklaida.
Pasinaudojus pirmuoju
duomenų trečdaliu buvo ieškomi a koeficientai, naudojant
antrąjį buvo rastas optimalus
atsimenamų į praeitį laiko momentų
kiekio intervalas, šio tyrimo
metu bus naudojama trečioji
duomenų dalis.
Atliekant
tyrimą su „Call Center“ duomenimis buvo
prognozuojami skambučių kiekiai nuo 241
iki 360 laiko momento (dienos) atsimenant į praeitį tai kas buvo per paskutines
19 dienų ir kiekvienos dienos prognozei imant realius praeities duomenis.
Prognozuojami skambučių kiekiai
buvo lyginami su realiais ir skaičiuojama
vidutinė modelio paklaida.

9 pav. Prognozavimas AR-ABS modeliu naudojant „Call Center“ duomenis
Kaip matyti iš paveikslėlio
prognozė pakankamai gerai seka realius
duomenis, o vidutinė absoliutinė paklaida yra
472,45 (kas sudaro 25% vidutinio skambučių kiekio
per 241-360 dienas). Paklaidos didumą tikslingiau būtų lyginti su svyravimais
pačiuose duomenyse:
-
Paklaida yra beveik du kartus mažesnė nei vidutinis absoliutinis nuokrypis (lygus 865,39) duomenyse
(trečiojoje duomenų dalyje, pagal kurią
ir buvo ieškoma vidutinė AR-ABS modelio daroma paklaida);
-
Paklaida yra 2,4 karto mažesnė
nei standartinis nuokrypis (lygus 1128,32) toje pačioje duomenų imtyje;
Analogiškai atliekant tyrimą
su AT&T duomenimis
buvo prognozuojamas akcijų kursas
nuo 306 iki 459 dienos atsimenant į praeitį tai kas buvo per paskutines
23 dienas.
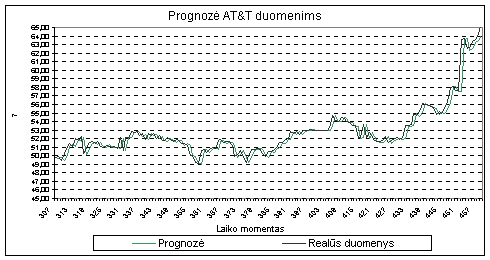
10 pav. Prognozavimas AR-ABS
modeliu naudojant AT&T
kompanijos duomenis
Vidutinė
absoliutinė paklaida prognozuojant AT&T
kompanijos akcijų kursą yra 0,48 (kas sudaro 0,91% vidutinio akcijų kurso per
306-459 dienas).
-
Paklaida yra 4,2 karto mažesnė
nei vidutinis absoliutinis nuokrypis
(lygus 2,04) toje pačioje duomenų imtyje,
pagal kurią buvo ieškoma
vidutinė AR-ABS modelio daroma paklaida;
-
Paklaida yra 6,45 karto mažesnė
nei standartinis nuokrypis (lygus 3,10) toje pačioje duomenų imtyje;
Kadangi
prognozuojant tiek skambučių kiekį,
tiek akcijų kursą AR-ABS modelio daroma paklaida mažesnė ir už vidutinį absoliutinį, ir
už standartinį nuokrypį duomenyse,
galima daryti išvadą jog
šiuo modeliu galima prognozuoti.
Iš pirmo
žvilgsnio atrodytų jog prognozuojant akcijų kursą gauti
geresni rezultatai nei
skambučių kiekį, tačiau
prieš darant tokią išvadą
reiktų įvertinti svyravimus duomenyse. Pagal „Call Center“ duomenis vidutinis skabučių
kiekis per nagrinėtą periodą buvo
1890, o standartinis nuokrypis (1128, 32 ) duomenyse sudaro 60%
vidutinio skambučių kiekio. Pagal AT&T kompanijos duomenis vidutinis akcijų kursas per
nagrinėtą periodą buvo 52,87, o standartinis nuokrypis (3,10)
duomenyse sudaro 6% vidutinio akcijų kurso, todėl galima teigti jog Call center
duomenims budingas apytiksliai 10 kartų stipresnis svyravimas. Jeigu
akcijų kurso prognozės paklaidos ir
standartinio nuokrypio
santykis būtų 10 kartų didesnis
už skambučių prognozės
paklaidos ir standartinio
nuokrypio santykį būtų
galima teigti jog AR-ABS
modelis vienodai gerai prognozuoja ir
finansinius duomenis, tačiau kol santykis yra
6/2 tenka pripažinti jog modelis geriau prognozuoja nefinansinius
duomenis.
4.7
Išorinių faktorių įvertinimas
Šioje
AR-ABS modelio tyrimo
etape buvo bandoma išsiaiškinti, kaip
išorinių faktorių
įvertinimas įtakoja optimalų atsimenamų į praeitį duomenų kiekį,
a koeficientus
ir žinoma modelio daromą paklaidą. Kaip jau buvo minėta modelio teorinio tyrimo dalyje išoriniai faktoriai tai - aplinkos kitimo ar įvykių įtakojančių prognozę duomenys, pvz.: oro temperatūra,
reklaminė akcijos, varžybos
gali įtakoti skambučių
kiekį.
Atlikus
eilę bandymų su „Call Center“ duomenimis, buvo nustatyta jog
įvertinant išorinius
faktorius sumažėja optimalus
atsimenamų į praeitį laiko
momentų kiekis p. Jei
prognozuojant skambučių kiekį,
neatsižvelgiant į išorinius
faktorius, buvo nustatyta, kad optimalus parametras p lygus 19,
tai įvertinant ir išorinius faktorius šis
parametras sumažėja iki 6.
Toks atsimenamų į praeitį laiko
momentų kiekio sumažėjimas nepanaikina
modelio išskirto periodiškumo įvertinimo. Kaip jau buvo
minėta, skambučių kiekis labai
priklauso nuo to kas buvo
lygiai prieš savaitę, o kadangi parametras p nemažesnis
nei 6, tai prognozuojant bus
įvertinti ir išoriniai faktoriai
ir tai kas buvo prieš
savaitę. Kuomet vertinama
daugiau nei penki
išoriniai faktoriai atsimenamų į praeitį laiko momentų kiekis sumažėja iki 1, iš
to galima spręsti,
jog skambučių kiekio prognozė priklauso nuo
išorinių faktorių ir nebepriklauso nuo praėjusios savaitės
skambučių kiekių, be
to padidėja ir
AR-ABS modelio daroma paklaida
nuo 472,45 (neįvertinat
išorinių faktorių) iki 620. Todėl
turint duomenų apie
visą eilę išorinių faktorių reiktų atrinkti kelis
tuos, kurių įvertinimas pagerina prognozę.
Atliekant tyrimą
su „Call Center“ duomenimis galima stebėti, kad tie a koeficientai, kurie
nulemia pačių skambučių
įtaką prognozei išskyrus
pirmąjį beveik nesikeičia, o
šeštojo stipriai padidėja.
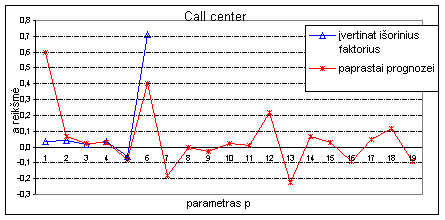
11 pav. a koeficientų įtaka prognozei įvertinant ir neįvertinat išorinių faktorių
Analizuojant a
koeficientus įtakojančius
išorinių faktorių svorį galima pasakyti jog labai didelė įtaką
prognozei turi šios dienos išoriniai faktoriai, didesnę negu
skambučių kiekis ankstesnėm dienom
ir taip pat didelę, bet neigiamą
įtaką turi tai, kokioje
būsenoje išoriniai faktoriai buvo prieš
savaitę žiūr. Priedas Nr.4.
Išorinių
faktorių įvertinamas prognozuojant skambučių
kiekį AR-ABS modeliu
sumažino prognozės paklaidą 9,6%
(nuo 472,45 iki 427,03), o prognozuojant ARMA
modeliu prognozės paklaida sumažėja 1,75% .
Kadangi
AT&T kompanijos duomenyse nėra informacijos apie išorinius
faktorius, panašus tyrimas buvo atliktas su Londono biržos
duomenimis. Čia įvertinus vieną išorinį
faktorių optimalus atsimenamų į praeitį lako momentų kiekis sumažėjo
nuo 4
iki 1, o prognozės paklaida sumažėjo 4,46%.
Apibendrinus galima pateikti tokias išvadas:
§
Įvertinant išorinius
faktorius sumažėja atsimenamų į praeitį laiko momentų kiekis;
§
Susilpnėja pačios laiko
eilutės duomenų įtaka prognozei;
§
Prognozės paklaida šiek
tiek sumažėja;
§
Kuomet vertinamas per
didelis išorinių faktorių kiekis
prognozės paklaida didėja.
4.8
AR- ABS, ARMA ir RW
modelių palyginimas
Tyrimo eigoje visa eilė
skaičiavimų buvo atliekama ne tik su Call center ir
AT&T kompanijos duomenimis,
bet ir su kitais Lentelėje Nr. 4
pateiktais duomenimis. Žemiau esančioje
lentelėje pateikiami apibendrinti tyrimo rezultatai.
Lentelė Nr. 6
|
Nr. |
Duomenys |
Vidutinis
nuokrypis duomenyse |
Paklaida RW |
Paklaida ARMA |
Paklaida AR- ABS |
Delta ARMA/RW |
Delta AR-ABS/ARMA |
|
1 |
$/£ |
0,0360 |
0,1145 |
0,1143 |
0,0060 |
-0,178% |
94,75% |
|
2 |
DM/$ |
0,0965 |
0,1092 |
0,1092 |
0,0088 |
-0,012% |
91,95% |
|
3 |
Yen/$ |
5,670 |
6,3006 |
6,3690 |
0,6434 |
-1,086% |
89,90% |
|
4 |
Fr/$ |
0,2857 |
0,4272 |
0,4285 |
0,0276 |
-0,303% |
93,55% |
|
5 |
AT/T |
2,2714 |
4,4922 |
4,5540 |
0,4824 |
-1,375% |
89,41% |
|
6 |
Intel Co |
10,36 |
20,58 |
20,52 |
0,9970 |
0,281% |
95,14% |
|
7 |
London Stock Exch. |
250,91 |
273,7 |
275,1 |
16,32 |
-0,511% |
94,07% |
|
8 |
Call Center |
825,66 |
1220,8 |
845,3 |
427,45 |
30,76% |
49,43% |
Iš
rezultatų pateiktų lentelėje galima spręsti jog AR-ABS modelis iš ties geriau prognozuoja
nei RW metodas, o taip pat ir ARMA
modelis tiek finansinius
tiek nefinansinius
duomenis. Ypač geri rezultatai gauti prognozuojant finansinius duomenis.
Tyrimo eigoje paaiškėjo jog
finansinių laiko eilučių prognozę
AR-ABS modeliu labiausiai įtakoja tai
kas buvo šiandien, ką ir teigė
profesorius J. Mockus. Lyginat su
ARMA modeliu, AR-ABS modelis
naudoja didesnį atsimenamų į praeitį
laiko momentų kiekį, tai ko gero sąlygoja paklaidų minimizavimui ir a
koeficientų radimui naudojamas
absoliutinių didumų, o ne mažiausių kvadratų
metodas. Paklaidų
absoliutiniais didumas minimizavimo metodu
rastieji a koeficientai
ir kartu didesnis atsimenamų į
praeitį laiko momentų kiekis žymiai geresnius prognozavimo rezultatus.
Išorinių faktorių
įvertinimas AR-ABS modelyje
labiau pagerina prognozę
nei ARMA modelyje.
AR-ABS modelis
yra mažiau jautrus duomenų
svyravimams nei ARMA modelis, tas
ypač išryškėja prognozuojant „Call Center“ priimamų skambučių kiekį (šiems duomenims palyginus
su finansiniais budingi dideli svyravimai). Tai akivaizdžiai matoma žemiau pateiktuose paveikslėliuose.

12 pav. Prognozė AR-ABS ir ARMA modeliais
13 pav. Paklaida prognozuojant AR-ABS ir ARMA modeliais
4.9 Prognozavimas eilę žingsnio į priekį ARMA ir AR-ABS modeliais
Šioje tyrimo dalyje buvo
tiriama, kokią paklaidą
daro modeliai prognozuojant eilę laiko momentų
į priekį nepapildant
laiko eilutės realiais duomenimis, o imant
prieš tai ėjusias
prognozes. Čia svarbu
į prognozę įtraukti ir baltąjį
triukšmą e t. Tai bus atsitiktinis dydis su Gauso pasiskirstymu e = G(0, σ) , kur σ - standartinis
nuokrypis AR-ABS modelio daromose paklaidose prognozuojant tą pačią duomenų imtį,
kuri buvo naudojama
a koeficientų radimui. Be
to, prognozė kartojama
kelis ar daugiau
kartų, minimali reikšmė
apibrėžia apatinę ribą,
maksimali viršutinę ribą, vidurkis imamas, kaip tikroji
prognozė.
Prognozės
AR-ABS modeliu „Call Center“
duomenis (pakartojimų kiekis - 10, atsimenamų į praeitį laiko
momentų kiekis - 6) rezultatai pateikti
žemiau esančiame paveikslėlyje.
13
pav. AR-ABS modelio prognozė eilei
laiko momentų
Atlikus eilę
bandymų pastebėta, jog
artima realiems duomenims
prognozė gaunama prognozuojant apie 25 dienas į priekį,
toliau prognozė beveik
nebeseka realių duomenų.
Prognozuojant ARMA
modeliu gaunamas kiek
kitoks vaizdas, tam įtakos
turi kitokia dispersija paklaidose
ir žinoma tai, jog
be baltojo triukšmo, prognozėje
įvertinama AR modelio daroma paklaida –
slenkantis vidurkis .

14
pav. ARMA modelio prognozė eilei
laiko momentų
Ir vieno, ir
kito modelis prognozuojant eilę laiko momentų
į priekį vidutinė paklaida gan
didelė: ARMA - 2669,6 ,
AR-ABS 1530,2 skambučių.
Prognozuojant eilę laiko momentų į
priekį praverstų vieno
ar kelių išorinių
faktorių būsenų ateityje
žinojimas. Prognozuojant
AR-ABS modeliu, priėmus
jog žinome ateityje
būsiančius išorinius faktorius vidutinė paklaida sumažėjo iki
759,5 t.y. dvigubai.
4.10 Klasifikavimo uždavinių sprendimas AR-ABS modeliu
Kaip jau
buvo analizuota antrajame skyriuje AR
modeliai (tuo pačiu ir AR -ABS)
su išorinių faktorių įvertinimu gali
būti taikomi įvertinti tiesinės regresijos parametrams. Skirtumas tas jog tokiu atveju t - žymės nebe laiko momentus, bet stebimų pavyzdžių kiekį, o AR modelio parametras p – bus lygus nuliui, nes
stebimi pavyzdžiai nepriklauso vienas
nuo kito.
ARMA modelio
pritaikymo galimybę klasifikavimo uždaviniams tyrė Rasa
Ruseckaitė lygindama ARMA modelio
rezultatus su dirbtinio intelekto metodo CHARADE
rezultatais. Tačiau ARMA modelis
nedavė gerų rezultatų. Remiantis
gautais rezultatais galima teigti, kad ARMA paprastos regresijos modelis
prognozuoja pacientus sergančius temporalinės skilties epilepsija su 70
procentų paklaida, o visus kitus - su 30 procentų paklaida [6].
Kadangi
nepavyko gauti epilepsijos
diagnozavimui naudotų duomenų,
AR-ABS modelio tyrimui
bus naudojami simbolių atpažinimui
pritaikyti duomenys. Duomenų pavyzdys buvo pateiktas
Lentelėje Nr. 2. Atskirai
bus analizuojamas
skaitmenų atpažinimas (duomenys
d1) ir atskirai įvairūs skyrybos
ženklai (duomenys d2).
Detaliau paanalizuokime klasifikavimo uždavinio
sprendimą bei rezultatus.
Jei toliau nagrinėtumėm Lentelėje Nr. 2. pateiktą failo fragmentą gautumėm tokius rezultatus:
Lentelė
Nr.7
|
Reali klasė |
Modelio pr. |
! |
? |
( |
|
! |
! |
1,000000 |
7,11E+00 |
3,87E+01 |
|
! |
! |
1,000000 |
2,12E+00 |
-4,16E-01 |
|
! |
! |
1,000000 |
2,73E+01 |
6,27E+01 |
|
? |
No Decision |
-0,103794 |
0,60933 |
0,535752 |
|
? |
? |
0,121673 |
0,98850 |
-0,14444 |
|
? |
? |
-0,130147 |
0,91610 |
0,261992 |
|
( |
( |
-1,94E+01 |
1,51E+01 |
1,000000 |
|
( |
( |
-1,26E+02 |
-1,39E+00 |
1,000000 |
|
( |
( |
-1,32E+02 |
-2,60E+01 |
1,000000 |
Kaip matyti
lentelėje, teisingai klasifikuoti aštuoni iš devynių
simbolių, ketvirtasis pavyzdys
taip pat būtų
teisingai klasifikuotas jei
mes nuspręstumėm pavyzdį priskirti
tai klasei, prie
kurios yra didžiausia
skaitinė reikšmė t.y.
0,60933, tačiau priklausomumo klasei „(“ reikšmė taip pat
palyginus didelė, todėl
kyla klausimas kokią
klasifikavimo principą ar taisyklę pasirinkti. Tuo
tikslu panagrinėsim kaip keičiasi rezultatai
keičiant patikimumo intervalą tiek normalizuotiems tiek ne duomenims
(rezultatai pavaizduoti grafike).
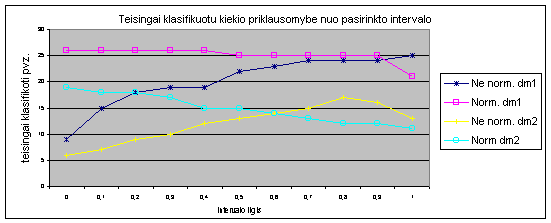
16 pav. Teisingai klasifikuotų pvz. kiekio
priklausomybė nuo pasirinkto patikimumo intervalo
Kuo
trumpesnis intervalo ilgis tuo su normuotais rezultatais teisingai
klasifikuojama daugiau pavyzdžių, o su
nenormuotomis priklausomumo reikšmėmis
atvirkščiai. Išlieka klausimas,
kokia klasifikavimo taisykle remtis, žinoma tai labai priklausys nuo
uždavinio taikymo. Bendru atveju, manau,
reiktų remtis rezultatais gaunamais nenormalizuotus duomenis apvalinant
pagal pasirinktą 0,7-0,8 intervalo ilgį t.y.
reikšmes iki 0,35-0,4
apvalinant į 0, reikšmes nuo 0,6- 0,65 apvalinat į 1, jei reikšmė pakliūva į 0,35-0,65
intervalą pavyzdys nėra nei
priskiriamas nei nepriskiriamas tai klasei.
Keičiant
pavyzdžių faktorių kiekį, svarbu pažymėti jog jį mažinant gaunami blogesni
rezultatai, žiūr. Lentelė Nr. 6, klasifikavimui naudoti nenormuoti duomenys ir
intervalas lygus 0,7, klasių kiekis -9.
Lentelė
Nr.8
|
Faktorių kiekis |
14 |
13 |
12 |
11 |
10 |
9 |
8 |
7 |
|
Teisingai klasif. |
96,15% |
88,46% |
69,23% |
69,23% |
50,00% |
34,62% |
15,38% |
11,54% |
Galima
nagrinėti vidutinės paklaidos priklausomybę nuo klasių kiekio bei
klasifikuojamų pavyzdžių kiekio.
Vidutinė paklaida - tai vidutinis skirtumas absoliutiniu didumu, kiekvieno pavyzdžio priklausomumo
reikšmę kiekvienai klasei atimant iš 1
arba 0. Gauti tyrimo rezultatai pateikti žemiau esančiame grafike.

17 pav. Vidutinės paklaidos priklausomybė nuo klasių kiekio
Iš
analizuojamų duomenų, negalima teigti, jog didėjant klasių ir klasifikuojamų pavyzdžių
kiekiui didėja vidutinė paklaida. Tačiau reikia pastebėti jog tokį tyrimą
riboja optimizavimo uždavinio išsprendžiamumas t.y. kai turima daug klasių
(šiuo atveju > 9), o tuo pačiu ir pavyzdžių pagal kuriuos ieškomi a
koeficientai , „lp_solve“ neberanda
optimalaus sprendimo.
Iš
turimų duomenų sunku tiksliai apibrėžti teisingai klasifikuojamų pavyzdžių
kiekio priklausomybę nuo klasių kiekio iš grafike stebimų tendencijų ir loginio
samprotavimo galima teigti, jog didėjant klasių kiekiui teisingai klasifikuojamų
pavyzdžių kiekis mažės.

18 pav. Teisingai klasifikuojamų pvz. kiekio priklausomybė nuo klasių kiekio
Apibendrinant galima pateikti tokias išvadas:
Prieš
pasirenkant taisyklę, pagal kurią būtų klasifikuojami objektai,
konkretiems duomenims
reiktų atlikti su
tais duomenimis nedidelį tyrimą,
prie kokio pasitikėjimo intervalo
ir su kokiais (normalizuotai ar
ne) rezultatais teisingai klasifikuojama daugiausiai
pavyzdžių ir atitinkamai pasirinkti
klasifikavimo principą.
Tyrimo metu
buvo nustatyta jog vidutinė
daroma modelio paklaida klasifikuojant simbolius (skaičius
ir atskirai skyrybos ženklus, kai kiekvienoj klasių grupėje yra po 9 klases)
yra 0,098 ir 0,238, o teisingai klasifikuojama atitinkamai 92% ir 78%
pavyzdžių.
Klasifikuojant AR-ABS modelio pagalba gaunami blogesni rezultatai nei sprendžiant
analogišką uždavinį dirbtinių neuroninių tinklų pagalba. Pastaruoju būdu
klasifikuojant apjungtas abi klasių grupes teisingai klasifikuojama 98% pavyzdžių (tyrimas buvo atliktas su kursinio
darbo metu realizuotu neuroniniu tinklu C programavimo kalba).
Apjungus abi klasių grupes
AR-ABS modeliu klasifikavimo uždavinys tapo neišsprendžiamu, kadangi „Lp_solve“ tiesinio
programavimo uždaviniui nerado
sprendinio. Tai galima
paaiškinti tuo, kad
„ Lp_solve “ TP uždavinius
sprendžia Simplekso algoritmu,
o kuomet yra
bent viena pora
tiesiškai arba beveik
tiesiškai priklausomų pavyzdžių,
matricos A determinantas lygus arba artimas 0 ir
Simplekso algoritmas neranda
optimalaus sprendinio. Turint
tik vieną vienos klasės pavyzdį nebūtų įmanoma
rasti a koeficientų
apibrėžiančių kokią nors
pavyzdžio priklausomumo taisyklę
nuo faktorių, todėl
daugėjant klasių kiekiui
žinoma padidės ir
pavyzdžių kiekis. Didėjant
pavyzdžių kiekiui didėja
ir tikimybė, kad
atsiras bent pora
tiesikai priklausomų pavyzdžių. Tad norint AR-ABS
modeliu spręst didesnius
klasifikavimo uždavinius, paklaidų
absoliutiniais didumais minimizavimui t.y. nelygybių sistemos
sprendimui reiktų pritaikyti
kitokį tiesinio programavimo algoritmą pvz. vidinio
taško metodą.
IŠVADOS
Šiame darbe
tiriamas mažai žinomas
auto regresinis mažiausių
absoliutinių nukrypimų
modelis AR-ABS. Šis modelis
tai klasikinio AR – modelio modifikacija, kur įprastas paklaidų
minimizavimui taikomas mažiausių
kvadratų metodas pakeistas
paklaidų absoliutiniais
didumais minimizavimu. Toks
optimizavimo uždavinys susiveda
į nelygybių sistemos
sprendimą. Tokios nelygybių
sistemos sprendimui šiame
darbe naudojamas vienas
iš tiesinio programavimo metodų – simplekso
algoritmas.
Atlikus AR –ABS modelio teorinį tyrimą buvo sukurta programinė šio modelio realizacija, kurios pagalba atliktas išsamus modelio tyrimas. Programa parašyta Java programavimo kalba, taip užtikrinant galimybę programą pilnai vykdyti Interneto priemonių pagalba. TP uždavinio sprendimui naudota Michael Berkelar sukurtas tiesinio programavimo paketas „Lp_solve“.
Modelio eksperimentiniam tyrimui buvo naudojami
skirtingų charakteristikų
duomenys: sunkiai prognozuojami finansiniai akcijų, valiutų kurso kitimo ir nefinansiniai, pasižymintys dideliais svyravimais
užsakymų priėmimo centro apkrovimo
duomenys. Skirtingiems duomenims skiriasi optimalus
atsimenamų į praeitį laiko momentų
kiekis. Duomenims, su kuriais
buvo atliekamas tyrimas, optimalus atsimenamų
į praeitį laiko momentų kiekis yra iš intervalo [5, 48]. a
koeficientų įtakos prognozei
tyrimas parodė, jog
prognozuojant finansinius duomenis
labai didelę įtaką prognozuojamai reikšmei turi pirmasis koeficientas, t.y. tai kas buvo šiandien, o visų likusių
įtaka labai silpna. Tai
reiškia, jog prognozuojant finansinius
duomenis AR- ABS modelis tarsi virsta Random Walk modeliu.
Analizuojant a koeficientų
įtaką užsakymų kiekio prognozei, nustatyta, kad prognozei
apylygiai didžiausią įtaką turi
tai kas buvo šiandien ir kas buvo prieš
savaitę. Tai rodo, jog nefinansiniuose duomenyse modelis neblogai išskiria pasikartojamumą.
Vidutinė daroma modelio paklaida visais atvejais buvo mažesnė (nuo 2 iki
15 kartų ) nei vidutinis absoliutinis nuokrypis duomenyse. Kuomet
įvertinami išoriniai faktoriai,
sumažėja optimalus atsimenamų į
praeitį laiko momentų kiekis, taigi prognozė tampa labiau
priklausoma nuo išorinių faktorių nei
nuo praeities, tą patvirtina ir a
koeficientų stebėjimai. Išorinių faktorių įvertinimas šiek tiek
sumažina AR-ABS modelio daromą vidutinę paklaidą.
Lyginant
prognozavimo rezultatus AR – ABS ir ARMA
modeliais, nustatyta jog
AR- ABS modelis beveik visais
atvejais naudoja didesnį optimalų
atsimenamų į praeitį laiko monetų kiekį.
AR- ABS modelis finansinius duomenis prognozuoja su apytiksliai 10 kartų mažesne paklaida nei
ARMA, užsakymų priėmimo telefonu duomenis prognozuoja su apytiksliai
2 kartus mažesne paklaida.
Tad AR-ABS modelis yra išties mažiau jautrus
dideliems duomenų svyravimams.
Tiriant
AR-ABS modelio pritaikymo galimybę klasifikavimo – diagnozavimo uždaviniams spręsti buvo naudoti skaitmenų ir skyrybos simbolių atpažinimui skirti duomenys. AR-ABS modelis teisingai klasifikavo atitinkamai 92% ir 78%
pavyzdžių, tačiau sprendžiant
didesnius klasifikavimo
uždavinius „Lp_solve“
nerado sprendinio. „Lp_solve “
TP uždavinius sprendžia
Simplekso algoritmu, o
kuomet yra bent
viena pora tiesiškai
arba beveik tiesiškai
priklausomų pavyzdžių, matricos
A determinantas lygus arba
artimas 0 ir Simplekso algoritmas neranda
optimalaus sprendinio. Tad
kol, kas galima teigti, kad AR-ABS
modelis naudojant simplekso algoritmą
TP uždaviniui spręsti neblogai
sprendžia nedidelius klasifikavimo uždavinius.
Ateityje, norint AR-ABS modelio pagalba spręsti didelius klasifikavimo uždavinius, simplekso algoritmą reiktų pabandyti pakeisti kitu tiesinio programavimo metodu pvz. vidinio taško metodu. Taip pat būtų įdomu patyrinėti slenkančio vidurkio įvertinimo įtaką daromai modelio paklaidai.
LITERATŪROS SĄRAŠAS
- A. Žilinskas. Matematinis
programavimas. Vytauto
Didžiojo universiteto leidykla,
2000. 227p.
- J. Mockus. A Set Of Examples Of Global And Discrete
Optimization KLUWER ACADEMIC PUBLISHERS second edition (in preparation to be
published).
- Jonas Mockus, William Eddy, Audris Mockus, Linas Mockus and Gintaras Reklaitis Baysian
heuristic approach and global
optimization. KLUWER ACADEMIC PUBLISHERS, 1996. 412 p.
- J. Kubilius. Tikimybių
teorija ir matematinė statistika: Vadovėlis.
Vilniaus universiteto leidykla, 1996.
439 p.
- T.S. Arthanari, Yadolah Dodge.
Mathematical Programing in Statistics 1993. 306 p.
- http://www.soften.ktu.lt/~mockus/
- ftp://ftp.es.ele.tue.nl/pub/lp_solve
- http://siesta.cs.wustl.edu/~javagrp/source/lp/
- http://www.pcgive.com/volume3.html
- http://www.css.orst.edu/sasdocs/books/ets/chap7/sect1.htm
PRIEDAI
Priedas Nr 1. TP uždavinys ir sprendinys sprendžiant skirtingom priemonėm.
Pateikiamas TP
uždavinys bei gauti rezultatai
sprendžiant skirtingomis priemonėmis.
Uždavinio formulavimas:
min:1.0 U1 + 1.0 U2 + 1.0 U3 + 1.0 U4 + 1.0 U5 + 1.0 U6;
1.0 U1 >= 62.5;
1.0 U2 + 62.5 a7 -62.5 a8 >= 62.875;
1.0 U3 + 62.875 a7 -62.875 a8 + 62.5 a9 -62.5 a10 >= 62.75;
1.0 U4 + 62.75 a7 -62.75 a8 + 62.875 a9 -62.875 a10 + 62.5 a11 -62.5
a12 >= 61.75;
1.0
U5 + 61.75 a7 -61.75 a8 + 62.75 a9 -62.75 a10 + 62.875 a11 -62.875 a12
+
62.5 a13 -62.5 a14 >= 61.75;
1.0
U6 + 61.75 a7 -61.75 a8 + 61.75 a9 -61.75 a10 + 62.75 a11 -62.75 a12 +
62.875 a13 -62.875 a14 >= 61.0;
-1.0 U1 <= 62.5;
-1.0 U2 + 62.5 a7 -62.5 a8 <= 62.875;
-1.0 U3 + 62.875 a7 -62.875 a8 + 62.5 a9 -62.5 a10 <= 62.75;
-1.0 U4 + 62.75 a7 -62.75 a8 + 62.875 a9 -62.875 a10 + 62.5 a11 -62.5
a12 <= 61.75;
-1.0 U5 + 61.75 a7 -61.75 a8 + 62.75 a9 -62.75 a10 + 62.875 a11 -62.875
a12 +
62.5 a13 -62.5 a14 <= 61.75;
-1.0 U6 + 61.75 a7 -61.75 a8 + 61.75 a9 -61.75 a10 + 62.75 a11 -62.75
a12 +
62.875 a13 -62.875 a14 <= 61.0;
Gautų rezultatų palyginimas pateiktas Lentelėje Nr. 9 :
Lentelė Nr. 9
|
Lp_solve(Java versija) |
Lp_solve(C versija) |
MATLAB |
|
ob_fn: 63.26127218 |
ob_fn: 63.26127218 |
63.2613 |
|
Var [1] 62.5 |
U1 62.5 |
62.5000 |
|
Var [2] 0.0 |
U2 0 |
0.0000 |
|
Var [3] 0.0 |
U3 0 |
0.0000 |
|
Var [4] 0.0 |
U4 0 |
0.0000 |
|
Var [5] 0.76127 |
U5 0.76127 |
0.7613 |
|
Var [6] 0.0 |
U6 0 |
0.0000 |
|
Var [7] 1.0059 |
a7 1.006 |
1.0060 |
|
Var [8] 0.0 |
a8 0 |
0.0000 |
|
Var [9] 0.0 |
a9 0 |
0.0000 |
|
Var [10] 0.00601 |
a10 0.00804 |
0.0040 |
|
Var [11] 0.0 |
a11 0 |
0.0000 |
|
Var [12] 0.01964 |
a12 0.01394 |
0.0080 |
|
Var [13] 0.00394 |
a13 0.00398 |
0.0140 |
|
Var [14] 0.0 |
a14 0 |
0.0000 |
Priedas Nr. 2 Programos naudojimo aprašymas
Programą „AR-ABS“ galima paleisti vykdymui interneto naršyklės pagalba surinkus atitinkamą internetinį adresą arba jei programos failai yra vietinėje sistemoje atsidaryti index.htm arba Applet1.html failus. Programą galima rasti tokiu internetiniu adresu: http://www.soften.ktu.lt/~mockus (Software Systems direktorijoje );
Pastaba, kadangi programos išeities kodas buvo sukompiliuotas JDK1.3 (JAVA DEVELOPMENT KIT) versija, interneto naršyklėje turi būti įdiegti JDK1.3 priedai (Plug-in) arba sistemoje instaliuota visas JDK1.3 paketas.
Programa taip pat galima paleisti vykdymui Appletviewer.exe programos pagalba (žinoma šiuo atveju, sistemoje turėtų būti instaliuota JDK). Iš JDK1.2.2 (ar aukštesnės versijos) direktorijoje esančios BIN direktorijos failą Appletviewer.exe reiktų nukopijuoti į direktoriją, kurioje randasi sukompiliuotų programos išeities tekstų klasių archyvas (ARABS.jar) ir galiausiai paleisti failą Run_ARABS.bat vykdymui. Nurodytame internetiniame puslapyje rasite nuorodą „arcive“, čia esančiame archyve pateikiami programa (visi išeities tekstai), duomenų failai, paleidžiamieji failai, bei aprašymas.
Programos išorinis interfeisas nėra apkrautas grafiniais elementais, tad norint naudotis programa neprireiks ypatingų įgūdžių, čia svarbiau bus suprasti parametrų apibrėžiančių konkretų AR-ABS modelį, bei skaičiavimų atlikimo scenarijų esmę.
Tik paleidus šią programą jūs išvysite tokį vaizdą:
19 pav.
Modelio langas
Žemiau
esančiame įvedimo lauke pagal
nutylėjimą nurodytas DNumber duomenų failas. Pasirinkus “Use data file
“ opciją duomenys bus imami
iš šio failo. Norint pasirinkti
kitą duomenų failą įvedimo lauke reikia surinkti
norimo failo, esančio tame
pačiame kataloge kaip ir
programa pavadinimą arba
nurodyti pilną kelią
iki failo. Pastaba, mygtukas „Browse….“ programą leidžiant
naršyklėje neveiks.
Iškilus problemoms pasirenkant failą visada galima atstatyti failą kuris buvo nurodytas tik ką paleidus programą, tereikia paspausti mygtuką „Default“. Pasirinkus „Enter data in a field“ opciją duomenys turės būti patalpinti po failo įvedimo lauku esančiame lauke.
Taip pat šiame lange galima pasirinkti, kokį uždavinį spręsime prognozavimo ar klasifikavimo-diagnozavimo. Sprendžiant prognozavimo uždavinį galima naudoti „call.data“ arba „armatest“ failus, o klasifikavimo „Dnumber“ arba „Dnumber0.txt“
Toliau galima pereiti į sekantį langą „Parameters“ (parametrai), jei sprendžiamas prognozavimo uždavinys jis atrodys sekančiai:
20 pav. Parametrų langas
Nors iš pirmo žvilgsnio šiame lange tėra tik keletas įvedimo laukų, tačiau reikia nepamiršti jog įvesti skaitmenys šiuose laukuose turės lemiamą reikšmę AR-ABS modelio sudarymui, atliekamų skaičiavimų specifikai bei gautų rezultatų pateikimo formai.
1. „Number of factors (M) :“ - įvedimo lauke galima įvesti skaičių iš intervalo [1; 32767]. Įvestas skaičius apibrėš išorinių faktorių kiekį, kurie bus įvertinami tiek sudarant konkretų AR-ABS modelį tiek prognozuojant sekančiam laiko momentui. M= 1 reikš jog atsižvelgiama tik į patį prognozuojamą didį ir jo reikšmes praeities momentais. Rekomenduojama, kad išorinių faktorių kiekis nebūtų didesnis nei duomenų failo eilutės elementų kiekis, priešingu atveju duomenys apibrėšiantys išorinius faktorius bus imami iš sekančių failo eilučių.
2. „AR parameter (p) :“ - įvedimo lauke galima įvesti skaičių iš intervalo [0;32767], jis apibrėžia laiko momentų į praeitį kiekį, kuriuos mes atsimename.
3. „Number of data entrees (T):“ - įvedimo lauke galima įvesti skaičių iš intervalo [1;32767]. Įvesta reikšmė apibrėš tariamai turimų duomenų kiekį. Duomenų kiekis (T) turi būti didesnis už antrajame lauke įvestą dydį.
4. „Indicator for one p evaluation (0), increasing p(1)“ - įvedimo lauke gali būti įvesta reikšmė 0 arba 1.
„0“ - reikš jog skaičiavimai bus atlikti vieną kartą su pasirinkta p reikšme.
„1“ - reikš jog skaičiavimai bus atlikti p kartų, pirmą kartą p=1, antrą p=2 ir t.t. Bus rastas optimalus p parametras, tai yra toks su kuriuo gaunami mažiausi nuokrypai prognozuojamų dydžių nuo realių.
5. „Indicator for one step evaluation (0), multistep (1)“ - šiame įvedimo lauke taip pat gali būti įvestas tik 0 arba 1.
„0“ - reikš jog prognozuosim tik vienam sekančiam laiko momentui T+1.
„1“ - reikš jog prognozuosim tokiam pat kiekiui laiko momentų, kokia buvo duomenų imtis T, t.y prognozuosim T+1, T+2, T+3 …T+T laiko momentams. Bus rastas vidutinis nuokrypis absoliutiniu didumu prie tam tikro parametro p.
6. „Indicator for multi days prognose (1):“ - šiame įvedimo lauke taip pat gali būti įvestas tik 0 arba 1.
„1“ - reikš jog prognozuosim tokiam pat kiekiui laiko momentų į ateitį kokia kokia buvo duomenų imtis T.
7. „ Number of multi days prognose repetitions K:“ –reikš kiek kartų, prognozuojant eilę laiko momentų į ateitį, kiekvienam laiko momentui bus kartojama prognozė.
Programa vykdo griežtą šių parametrų įvedimo kontrolę, neteisingai įvesta reikšmė yra atstatoma į paskutinę teisingą ir pranešama atitinkama perspėjimo žinute.
Jei sprendžiamas klasifikavimo uždavinys "Parameters" langas atrodys sekančiai:
1. „Number of factors (M) :“ – nurodoma kiek faktorių apibrėžia kiekvieną pavyzdį;
2. „Confidence value“ – reikšmė nuo 0 iki 1, 1 reikš jog priklausomumo reikšmei esant 1 bus vykdomas paprastas aritmetinis apvalinimas į 0 arba vienetą, o jei parinksime 0,4 – į 1 bus apvalinama tik didesnė arba lygios 0,8 reikšmės ir atvirkščiai į 0 mažesnės arba lygios 0,2.
3. „Number of data entrees (T)“ – nurodo kiek pavyzdžių bus naudojama sprendžiant optimizavimo uždavinį.
4. Po paskutiniu įvedimo lauku esančiame lauke patalpinti pavyzdžiai kuriuos modelis klasifikuos, pirmas simbolis nurodo klasę.

21 pav. Parametrų langas
Skaičiavimų („Calculation“) lange esančių mygtukų pagalba atliekami sekantys veiksmai:
§ Paspaudus mygtuką „Calculate“ vykdomi skaičiavimai;
§ Mygtuku „Stop“ skaičiavimai nutraukiami. Skaičiavimai nutraukiami baigus loginį skaičiavimų vienetą, o ne iš karto.
§ Paspaudus mygtuką „Graphic“ - atskirame lange bus pateiktas skaičiavimo rezultatų grafikas.
§ Paspaudus mygtuką „Detale results“ atskirame lange, bus pateikti detalūs rezultatai.
Vykdant skaičiavimus galimi pranešimai apie problemas atsiradusias skaitant duomenis iš failo.

22 pav. Skaičiavimų langas
Gauti skaičiavimo rezultatai prognozuojant analizuojami taip:
„p“ - atsiminimo į praeitį momentų kiekis;
„Predicted“ - sekantis prognozuojamas dydis;
„Should be“ - koks iš tikrųjų dydis turėtų būti;
„Residuals“ - nuokrypis prognozuojamo nuo tikrojo dydžio;
„Sum of all residuals“ - suma visų nuokrypių absoliutiniu didumu;
„The average of residuals“ - vidutinis nuokrypis;
„The optimal p parameter:“ - optimali p parametro reikšmė.
Parinkus kitokius parametrus skaičiavimo kontrolei galimi šiek tiek kitokie rezultatų pateikimo atvejai, tačiau raktiniai žodžiai išlieka tokie patys.
Detalesni rezultatai pateikiami atskirame lange, kuris
aktyvuojamas paspaudus „Detaled
rezults“ mygtuką.
23. pav. Detalių rezultatų langas sprendžiant
prognozavimo uždavinį
Sprendžiant klasifikavimo uždavinį
gauti rezultatai analizuojami
sekančiai:
„Class“ – priklausomumo kiekvienai klasei suapvalinta reikšmė;
„Should be“ – kokiai klasei iš tikrųjų priklauso pavyzdys;
„Calculated“ – kokiai klasei naująjį pavyzdį priskyrė modelis;
„Number of examples“ – klasifikuojamų pavyzdžių kiekis;
„Number of rigth clasified examples“ –teisingai klasifikuotų pavyzdžių kiekis.

24.
pav. Detalių rezultatų langas sprendžiant klasifikavimo uždavinį
Kuomet sprendžiamas prognozavimo uždavinys paspaudus „Calculation“ lange esantį mygtuką „Graphic“ (mygtukas bus aktyvus jei „Parameters“ lange „Indicator for one p evaluation (0), increasing p(1)“ įvedimo lauke buvo įvesta reikšmė -1) lange „Residuals graphic“ bus pateiktas grafinis nuokrypio priklausomybės nuo parametro p atvaizdavimas.

25. pav. Nuokrypio priklausomybės nuo p grafikas
Iškilus problemų naudojantis programa ar pamiršus esančių objektų (mygtukų, įvedimo laukų ir kt.) paskirtį galima iškviesti pagalbos langą „HELP Window…“ pavaizduotą 20 pav. Paspaudus dešinį pelės klavišą bet kuriame iš trijų pagrindinių langų („Model“, „Parameters“, „Calculation“) atsiranda mygtukas „Help..“, jį paspaudus atsidaro „HELP Window…“ langas.

26 pav. Pagalbos langas
Priedas Nr. 3 a koeficientų įtaka AR-ABS modelio prognozei
Kuomet atsimenamų į praeitį laiko momentų kiekis artėja prie duomenų imties naudojant
Call Center ir AT&T kompanijos duomenis a koeficientų įtaka pavaizduota žemiau esančiuose
paveikslėliuose.
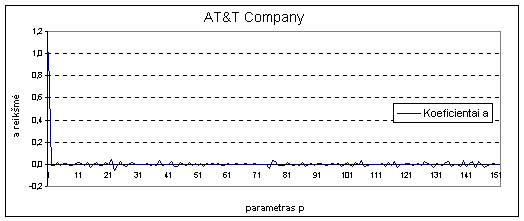
27 pav. a koeficientų
įtaka AT&T kompanijos duomenims
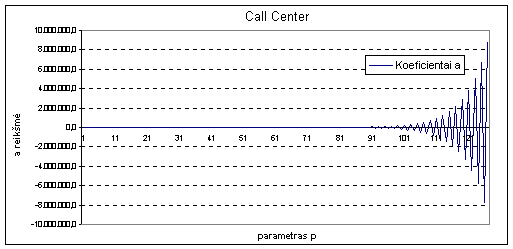
28 pav. a koeficientų
įtaka „Call Center“ duomenims
Priedas Nr. 4 AR-ABS modelio a koeficientai ir prognozė įvertinant išorinius faktorius
Naudojant „Call Centr“ duomenis:
Lentelė Nr. 10
|
Laiko momentas |
a koeficientas
skambučių kiekiui |
A koeficientas
išoriniam faktoriui |
|
1 |
0,036427 |
1734,944 |
|
2 |
0,039272 |
-232,989 |
|
3 |
0,016082 |
107,7073 |
|
4 |
-244,488 |
|
|
5 |
-0,0625 |
177,3322 |
|
6 |
0,710848 |
-1218,76 |

29. pav. Prognozės palyginimas su prognoze įvertinant išorinius faktorius
Priedas Nr. 5 AR-ABS modelio prognozės finansiniams duomenims
30 pav. $/£ Prognozė AR-ABS modeliu

31 pav. Paklaida prognozuojant $/£ kursų kitimą AR-ABS modeliu
32 pav. DM/$ kurso kitimo prognozė AR-ABS modeliu
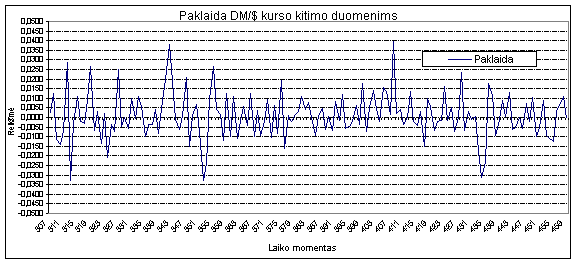
33 pav. Paklaida prognozuojant DM/$ kursų kitimą AR-ABS modeliu
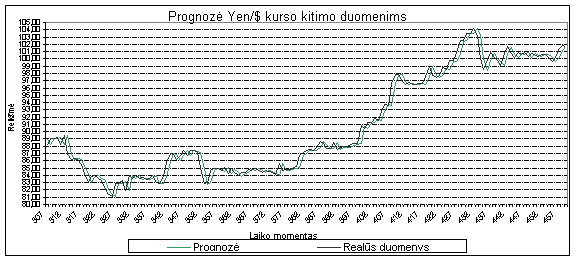
34 pav. Yen/$ kurso kitimo prognozė AR-ABS modeliu
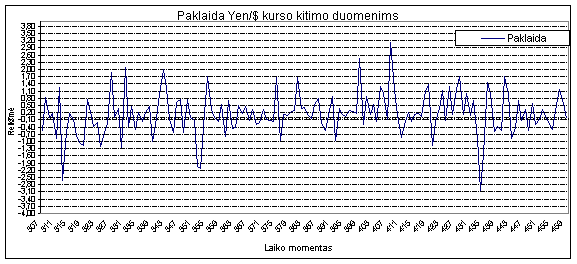
35 pav. Paklaida prognozuojant Yen/$ kursų kitimą AR-ABS modeliu

36 pav. Fr/$ kurso kitimo prognozė AR-ABS modeliu

37 pav. Paklaida prognozuojant Fr/$ kursų kitimą AR-ABS modeliu

38 pav. Intel Co akcijų kurso kitimo prognozė AR-ABS modeliu
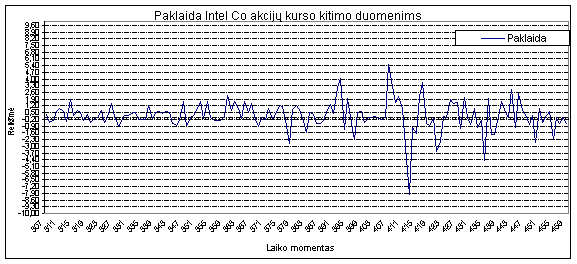
39 pav. Paklaida prognozuojant Intel Co akcijų kurso kitimą AR-ABS modeliu
40 pav. Londono biržos indekso kitimo prognozė AR-ABS modeliu

41 pav. Paklaida prognozuojant Londono biržos indekso kitimą
AR-ABS modeliu